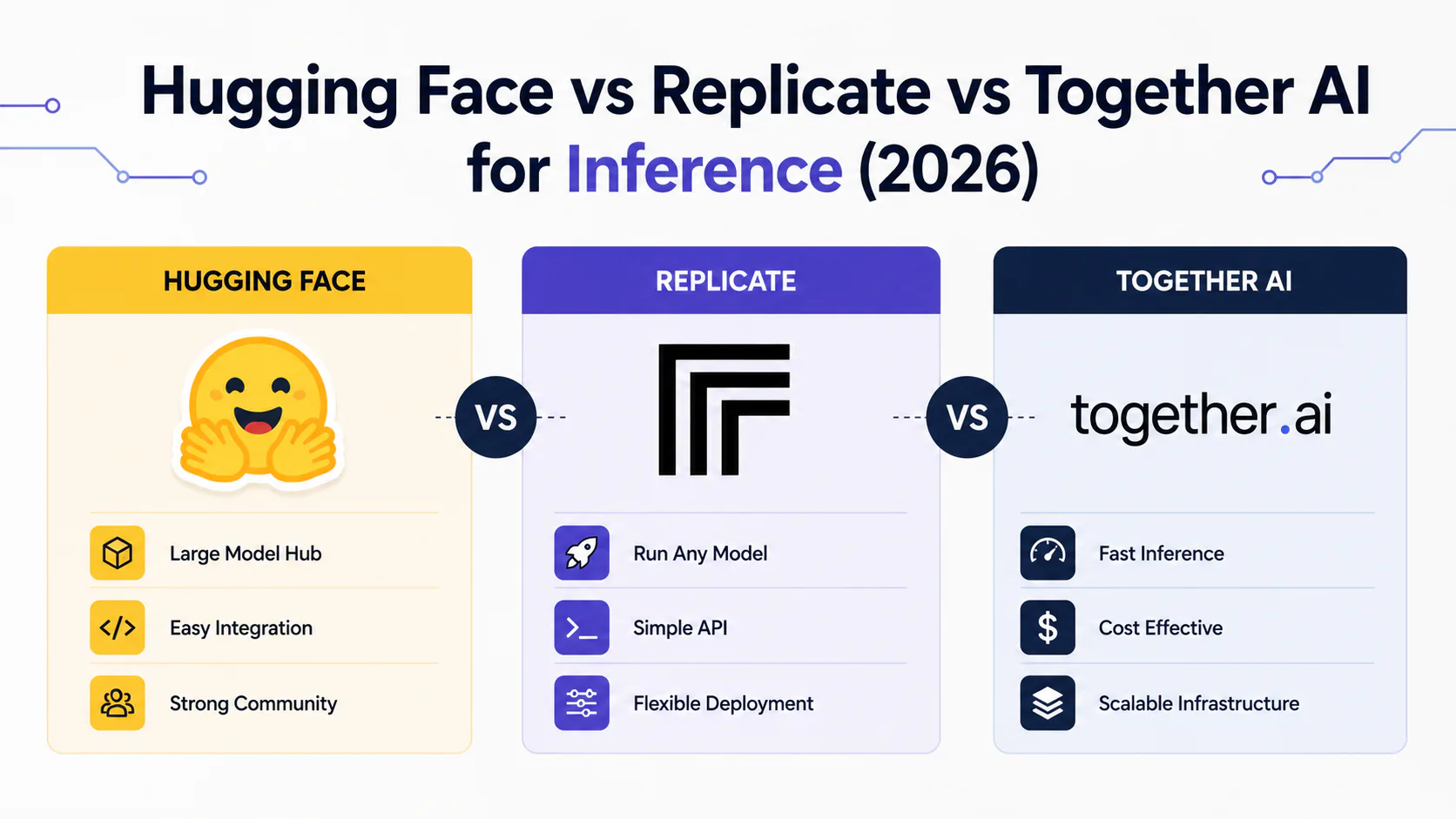
Hugging Face vs Replicate vs Together AI for Inference (2026)
Hugging Face, Replicate (now Cloudflare), and Together AI compared on pricing, model catalog, performance, and which platform suits your workload in 2026.
Picking the wrong AI inference platform doesn't just cost money. It either burns you on idle GPU hours for a low-traffic tool, or leaves you throttled and under-provisioned when a production workload actually needs throughput.
Hugging Face, Replicate, and Together AI are the three platforms most developers compare when they move past the OpenAI API and need to run open-source models themselves. They're often described as direct competitors. Under the hood, they're built on fundamentally different philosophies: model discovery versus API simplicity versus raw inference performance.
This comparison covers current pricing, architecture, and production deployment data as of June 2026, including one development that materially changes the Replicate picture: Cloudflare's acquisition of the company in November 2025 for a reported $550 million.
TL;DR: Together AI wins for production LLM inference speed and enterprise workloads. Replicate (now part of Cloudflare) wins for zero-config access to niche and community models. Hugging Face Inference Endpoints wins when your team needs to fine-tune, deploy, and manage the full ML lifecycle in one place.
Quick verdict
Together AI is the fastest option for open-source LLM inference, and its estimated $1 billion annualized revenue run rate as of February 2026 is hard evidence the market agrees. Replicate is the lowest-friction path from "I found a model I want to run" to a working API call, now backed by Cloudflare's global edge network. Hugging Face Inference Endpoints is the right choice when your team lives in the Hub ecosystem and needs to deploy models you've fine-tuned yourselves.
None of these wins on every dimension. The wrong platform for your workload will cost you more than the right one, either in wasted compute spend or engineering time.
What each platform actually is
Understanding the problem each platform was originally designed to solve is the fastest way to predict which one fits your situation.
Hugging Face Inference Endpoints
Hugging Face is, first and foremost, a model discovery and community platform. The Hub hosts over 2 million models, datasets, and demos, and is where most open-source model releases land first. Inference Endpoints is its paid, dedicated infrastructure deployment product layered on top of that Hub. You pick a model from the Hub, choose GPU hardware (from NVIDIA T4 to H100), configure autoscaling, optionally enable scale-to-zero for idle periods, and set up private networking via AWS or Azure PrivateLink for compliance requirements.
Billing is hourly per deployed replica, calculated by the minute. You pay for the GPU whether or not it's actively serving requests, unless scale-to-zero is configured and your traffic pattern allows for it.
Replicate (now part of Cloudflare)
Replicate's founding premise was that most developers don't want to manage GPU infrastructure, Docker containers, or autoscaling configurations. They want to pick a model, send input, and get output. The platform built this around Cog, an open-source tool that packages any ML model into a standardized container that Replicate can host and expose via API.
Because any developer can Cog-package and publish a model, Replicate has accumulated over 50,000 community-published, immediately deployable models: the largest ready-to-run inference catalog in the space. Billing is pay-per-second of compute time, or pay-per-output for some image and video models, meaning idle periods cost nothing.
In November 2025, Cloudflare acquired Replicate for a reported $550 million. Cloudflare's stated goal is to integrate Replicate's model catalog into Cloudflare Workers AI and enable edge-distributed inference globally. Cloudflare has explicitly committed that existing APIs and all currently running models remain unchanged, and Replicate continues to operate as a distinct brand.
Together AI
Together AI was founded on a specific thesis: the standard open-source serving frameworks most platforms use don't fully use the hardware they run on. The company is led by researchers, including Chief Scientist Tri Dao, who created FlashAttention, and its inference engine is built on custom kernel optimizations rather than off-the-shelf stacks.
The result is documented performance advantages: up to 4x throughput improvement at long sequence lengths via FlashAttention 4, and up to 3.6x gains for agentic workloads via a system called ThunderAgent. Together AI offers both serverless pay-per-token inference and dedicated GPU endpoints with guaranteed throughput, alongside provisionable clusters scaling from single 8-GPU nodes to deployments with hundreds of interconnected H100 or B200 GPUs. By February 2026, the company had reached an estimated $1 billion in annualized revenue, one of the fastest infrastructure revenue ramps on record in AI.
Model catalog: breadth versus curation
This is the dimension where the platforms diverge most sharply, and it determines whether you can even run the model you want.
Hugging Face has the largest raw model count by far: over 2 million models, including research uploads, private models, and community fine-tunes. Not every model in the Hub can be deployed directly as an Inference Endpoint (architecture and format compatibility varies), but the Hub is where most open-source model releases land first. If a model exists, it's almost certainly here.
Replicate has over 50,000 Cog-packaged, immediately deployable models. This is the largest ready-to-run inference catalog of the three platforms. Critically, it includes substantial coverage of niche generative media models (Stable Diffusion variants, community fine-tunes, research pipelines) that aren't available on Together AI's curated list and aren't pre-packaged for direct deployment on Hugging Face Endpoints. If you need a specific community-fine-tuned image model or a research pipeline that hasn't hit the mainstream, Replicate is the most likely place to find it already packaged and callable.
Together AI offers approximately 200 curated, pre-optimized open-source models. This is intentionally narrow: every model Together AI hosts has been benchmarked, quantized, and optimized to run on its inference engine, which is how the platform delivers its performance advantages. You won't find obscure fine-tunes or research models here, but the models they do support will typically run faster and at lower latency than the same model hosted on a standard serving stack.
Note: Hugging Face has begun integrating Replicate as an inference provider within its own ecosystem, letting Hub users run models through Replicate's infrastructure without switching platforms. Even before the Cloudflare acquisition, these two platforms were moving toward complementary positioning rather than pure head-to-head competition.
Pricing: three fundamentally different billing models
This comparison is not about which platform is "cheaper" in the abstract. The three platforms use genuinely different billing architectures, and the most cost-effective option depends entirely on your traffic shape.
Traffic pattern HF Endpoints (hourly) Replicate (per-sec) Together AI (token/cluster)
──────────────────────────────────────────────────────────────────────────────────────────────────
Sustained high traffic ✓ Good amortization ✗ Higher per-request ✓ Dedicated endpoint
Sporadic / variable ✗ Idle GPU waste ✓ Zero idle cost ✓ Serverless tier
Guaranteed throughput ✓ Reserved replicas ✗ Not available ✓ Dedicated + clusters
Edge / low latency ✗ Centralized only ✓ Cloudflare edge (new) ✗ Centralized clusters
Fine-tune + deploy ✓ Integrated workflow ✗ Inference-only PartialHugging Face: hourly per-replica
Inference Endpoints bill by the minute based on the hardware tier you deploy. CPU instances start around $0.03/hour; GPU instances start roughly $0.50/hour for T4-class hardware, scaling upward for A10G, A100, and H100 options. The economic logic: if your endpoint is consistently handling requests, you pay a fixed rate that amortizes well over high throughput. If traffic is sparse or variable, you're paying for idle GPU time regardless of usage.
Scale-to-zero is configurable and meaningfully reduces cost for tools with predictable downtime patterns, but it introduces cold-start latency when the endpoint wakes from zero.
Replicate: pay-per-second compute
Replicate charges by the second of GPU compute time, or per output for some image and video models. If a model isn't actively running, you pay nothing. This makes Replicate economically well-suited for internal tools, side projects, and any application where traffic is unpredictable or bursty. The trade-off: for a continuously loaded production LLM API, per-second billing can cost more than a well-utilized Hugging Face endpoint or Together AI dedicated instance.
Together AI: serverless plus dedicated
Together AI is the only platform offering both billing models in one place. The serverless tier charges per token (input and output), with no charge during idle periods. This is structurally similar to Replicate's billing for variable workloads, but running on Together AI's performance-optimized infrastructure.
For teams with predictable, high-volume needs, dedicated endpoints provide guaranteed throughput at a fixed hourly rate: roughly $1.76 to $2.39 per GPU-hour for HGX H100, and $4.00 to $5.50 per GPU-hour for Blackwell B200 hardware, depending on commitment length. Instant Clusters extend this to hundreds of interconnected GPUs for large deployments.
Pricing caveat: The same open-source model can cost meaningfully different amounts across providers. Llama 4 Maverick reportedly costs roughly 20% more for input tokens on Together AI than on Fireworks AI, reflecting infrastructure efficiency differences rather than model differences. Always benchmark your specific model and traffic pattern before committing to a platform.
Inference performance: where Together AI has a measurable edge
Performance comparisons in the inference hosting space are frequently overstated, so it's worth being specific about what Together AI's advantage actually is and where it matters in practice.
Together AI's engine is built on FlashAttention and its successors, custom attention kernels that significantly reduce memory bandwidth requirements during inference, particularly at long sequence lengths. FlashAttention 4 delivers up to 4x throughput improvement at long contexts. ThunderAgent, a separate optimization focused on agentic workload patterns, delivers up to 3.6x throughput gains for agent loops. A third layer called ATLAS-2 adds roughly 1.5x additional speedup on top.
In third-party assessments, these optimizations have produced up to 3.5x faster inference than standard deployments for the same models. For a customer-facing chat feature running Llama 3.1 70B with tight latency requirements, Together AI's engine will typically produce better throughput and lower latency than the same model on a standard TGI stack (which is Hugging Face Endpoints' default serving framework). For a niche Stable Diffusion fine-tune running as an internal creative tool with three requests a day, the performance difference is irrelevant and Replicate's simplicity wins decisively.
Platform comparison
| Feature | Hugging Face Endpoints | Replicate (Cloudflare) | Together AI |
|---|---|---|---|
| Model catalog size | 2M+ Hub models | 50,000+ Cog models | ~200 curated |
| Billing model | Hourly per replica | Per-second / per-output | Serverless (token) + dedicated |
| Idle cost | ✗ Charged unless scale-to-zero | ✓ Zero idle cost | ✓ Zero on serverless tier |
| Scale-to-zero | ✓ Configurable | ✓ Default behavior | ✓ Serverless tier |
| Fine-tuning support | ✓ AutoTrain + LoRA/QLoRA | Partial | ✓ Supported |
| Edge deployment | ✗ | ✓ Cloudflare Workers AI | ✗ |
| Dedicated hardware | ✓ Reserved replicas | ✗ | ✓ Endpoints + clusters |
| Private networking | ✓ AWS/Azure PrivateLink | ✗ | ✓ |
| SOC 2 / HIPAA | ✓ Enterprise Hub | ✗ (via Cloudflare) | ✓ SOC 2 Type II, HIPAA |
| Zero data retention | ✗ | ✗ | ✓ |
| Custom Docker container | ✓ | ✓ (Cog) | ✗ |
| OpenAI-compatible API | Partial | ✗ | ✓ |
| Proprietary model access | ✗ | ✓ (some via Cog) | ✗ |
| Owned infrastructure | Leased | Edge (Cloudflare) | Owned data centers |
| Starting GPU price | ~$0.50/hr (T4) | Per-second (varies) | Serverless from ~$0.18/1M tokens |
When to choose Hugging Face Inference Endpoints
Hugging Face is the right call when inference is the last step in a workflow that also involves training, fine-tuning, and evaluation. No other platform integrates the full ML lifecycle: AutoTrain for no-code fine-tuning, Transformers with LoRA and QLoRA for code-level training, Hub versioning for model management, and Inference Endpoints for deployment in a single environment. If your team fine-tunes base models and wants to deploy them without moving to another platform, Hugging Face is the natural home.
It's also the better choice when you need granular infrastructure control: picking specific GPU hardware tiers, configuring autoscaling policies precisely, setting up AWS or Azure PrivateLink for VPC-isolated deployments, or keeping models in a specific cloud environment for regulatory reasons. Neither Replicate nor Together AI gives you this level of per-instance hardware selection.
The clear disadvantage is the billing model. For any workload with variable or unpredictable traffic, you're paying for idle GPU time unless scale-to-zero is tuned carefully. And for raw inference speed on the models Together AI supports, Hugging Face's default TGI stack won't match Together's proprietary kernels.
Choose Hugging Face Inference Endpoints if:
- Your team trains or fine-tunes models and needs the full ML lifecycle in one platform
- You need granular hardware selection (specific GPU tier) and infrastructure control
- Your workload has sustained, predictable throughput that amortizes hourly billing effectively
- Private networking or cloud-specific compliance requirements rule out other providers
- You need to deploy models that aren't in Together AI's 200 curated options or pre-packaged on Replicate
When to choose Replicate
Replicate wins when you need something working immediately without becoming an infrastructure engineer, or when the model you need is niche enough that it only exists in the Cog ecosystem.
The clearest use case: you found a specific community-fine-tuned image model, a research pipeline from a paper's GitHub repo, or a Stable Diffusion variant with custom LoRA training, and you need to call it from your app today. Replicate's 50,000+ Cog models make this uniquely solvable here. Hugging Face's 2 million Hub models are larger by raw count, but most haven't been pre-packaged for zero-friction inference API calls the way Cog-published models have.
The pay-per-second billing model makes Replicate structurally well-suited to variable traffic applications: internal tools, side projects, batch jobs that run on a schedule, or prototypes that might see zero traffic most of the day. Paying only when the model runs eliminates the cost waste of idle GPU hours that Hugging Face's hourly model can impose on low-traffic deployments.
Post-acquisition, Replicate is gaining access to Cloudflare's edge infrastructure. For latency-sensitive, globally distributed applications, running inference physically close to users across Cloudflare's 300-plus data center locations is a capability that's becoming available through Replicate in a way that wasn't possible 12 months ago. This integration is still maturing, but it's worth evaluating closely if global distribution matters for your product.
Choose Replicate if:
- You need a niche, community-packaged, or research model not available on the other platforms
- Your traffic is variable, sporadic, or unpredictable and zero idle cost is important
- You want the fastest path from "found a model" to "working API integration"
- Edge-based inference for globally distributed users is a near-term requirement
If you're building AI-powered agent pipelines and thinking about how inference platform choices interact with production quality gates, our guide to guardian agents in CI/CD pipelines covers that intersection in detail.
When to choose Together AI
Together AI is the production inference platform for teams where speed, guaranteed throughput, and enterprise compliance are actual requirements and not preferences.
If you're running Llama 3.1, DeepSeek-R1, Mixtral, or Qwen at meaningful scale for a customer-facing product, Together AI's proprietary inference engine produces better throughput and lower latency than generalist platforms using standard serving stacks. Enterprise customers include Salesforce, Zoom, and The Washington Post, which is a reasonable signal that the reliability claims hold at production scale. The OpenAI-compatible API also means migrating an existing OpenAI integration is straightforward: change the base URL and the model name, and most code requires no other modification.
The model catalog limitation is real. Roughly 200 curated models means you probably can't find a niche community fine-tune here. But every model Together AI hosts has been benchmarked and optimized, and the billing flexibility (serverless for variable loads, dedicated for guaranteed throughput) means you don't have to switch platforms as volume grows predictable.
Together AI's shift toward owning its own data centers is worth noting for long-term platform risk assessment. With a Maryland facility live since July 2025, a Memphis facility incoming, and a partnership with Hypertec and 5C Group targeting up to 100,000 NVIDIA Blackwell and next-generation GPUs across Europe through 2028, the company is moving from a pure capacity-leasing model toward owned infrastructure. This should improve unit economics as inference volumes scale.
Choose Together AI if:
- You're running major open-source LLMs (Llama, DeepSeek, Mixtral, Qwen) at production scale
- Inference speed and throughput are measurable requirements, not preferences
- You need dedicated endpoints with guaranteed throughput or provisioned multi-GPU clusters
- Enterprise compliance is required: SOC 2 Type II, HIPAA, zero data retention, EU data residency
- You want the flexibility to start on serverless billing and graduate to dedicated as volume grows
For broader context on how the open-source model landscape is shifting in 2026, including recent frontier model launches from Meta, Anthropic, and others, the weekly AI roundup covers the key developments.
Which one should you choose?
For most application developers building on open-source models at early scale: start with Together AI's serverless tier. The OpenAI-compatible API makes integration trivial, you pay only for tokens processed, and you're on infrastructure that can scale without a platform migration as traffic grows.
For teams doing active ML work (fine-tuning, evaluating, iterating on models): Hugging Face Inference Endpoints is the right platform. No other option integrates the complete workflow from training to deployment in a single environment.
For niche generative media pipelines or variable-traffic applications: Replicate is the clear winner. The community model catalog is unmatched, and pay-per-second billing is the most cost-efficient structure for any application where usage is unpredictable or bursty.
The Cloudflare acquisition is the wildcard in this picture. If edge-based inference proves to be a meaningful differentiator (and Cloudflare's track record and infrastructure investment suggest they'll push it hard), Replicate's positioning could shift considerably over the next 12 to 18 months. For teams building globally distributed, latency-sensitive AI features, it's worth watching whether the Cloudflare Workers AI integration delivers on its promise.
Frequently asked questions
Yes. Cloudflare announced the acquisition of Replicate in November 2025, with the deal reported at up to $550 million (exact terms were not officially disclosed). Cloudflare committed that existing APIs and all currently running models remain unchanged, and Replicate continues to operate as a distinct brand. The longer-term goal is to integrate Replicate's 50,000-plus model catalog into Cloudflare Workers AI for edge-distributed inference closer to end users.
The billing models are structurally different, making a direct comparison depend entirely on your traffic pattern. Hugging Face charges hourly per deployed GPU replica regardless of traffic, starting around $0.50/hour for T4-class hardware. Together AI's serverless tier charges per token processed with zero cost during idle periods. For variable or sporadic workloads, Together AI's serverless tier is typically cheaper. For consistently high-throughput workloads, Hugging Face's hourly model can be more cost-effective once the replica stays near full utilization.
Cog is Replicate's open-source tool for packaging machine learning models into standardized containers that Replicate can host and expose via API. Any developer can Cog-package a model and publish it, which is why Replicate has accumulated over 50,000 community-published, immediately deployable models. It's the primary reason Replicate has broader coverage of niche and community fine-tuned models than either Hugging Face Inference Endpoints or Together AI.
Yes, and the evidence is substantial. Together AI has documented enterprise customers including Salesforce, Zoom, and The Washington Post, and reached an estimated $1 billion in annualized revenue by February 2026. The platform offers SOC 2 Type II certification, HIPAA compliance, zero data retention options, and dedicated endpoints with guaranteed throughput. For open-source LLM inference at production scale, it's the most performance-focused of the three platforms in this comparison.
The answer depends on what you mean by "available." Hugging Face Hub hosts over 2 million models in total, making it the largest raw repository. Replicate has over 50,000 Cog-packaged models that are immediately callable via API, the largest ready-to-run inference catalog. Together AI offers roughly 200 curated, pre-optimized models. If you need a specific niche model, check Replicate first. If you need to deploy a model you've trained yourself, Hugging Face has the most complete workflow.
Yes, and it's a practical pattern for teams doing active ML work. You can fine-tune a model using Hugging Face's tooling (AutoTrain, Transformers, LoRA), push the base weights to the Hub for versioning and sharing, and then route production inference traffic to Together AI's serverless tier for better throughput, or to Hugging Face Inference Endpoints if you need to deploy the exact fine-tuned variant. The two platforms are not mutually exclusive, and many production ML teams use multiple providers depending on workload requirements.