Muse Spark vs DeepSeek V4: Open-Source Model Shootout (2026)
Meta Muse Spark vs DeepSeek V4 compared on benchmarks, pricing, licensing, and real-world use. Find out which model belongs in your AI stack in 2026.

April 2026 handed the AI industry two models that couldn't be more different and can't easily be ignored. Meta launched Muse Spark on April 8, its first proprietary frontier model and a deliberate reversal of the open-source commitment that defined the Llama era. DeepSeek launched V4 sixteen days later under an MIT license, with a 1 million token context window and pricing that undercuts every closed-source competitor.
The timing made a comparison inevitable. But this isn't just a benchmark battle. The choice between these two models carries licensing implications, geopolitical risk, cost structure consequences, and architectural trade-offs that affect which workloads are even viable to build. If you're evaluating either for production use, you need to understand all four.
This post compares Muse Spark and DeepSeek V4 across the dimensions that actually matter for developers and engineering teams making a real decision.
TL;DR: DeepSeek V4-Pro is the better choice for cost-sensitive, high-volume, or self-hosted workloads. Muse Spark wins for health, multimodal, and consumer-facing applications inside Meta's platforms. Neither model is the best in the world overall - but both reshape what's economically viable to build.
Quick verdict
DeepSeek V4 is the more versatile workhorse. Its MIT license, 1M token context, OpenAI-compatible API, and aggressive pricing make it the default recommendation for most developer use cases. Muse Spark earns its place in specific verticals - healthcare, multimodal figure analysis, and Meta platform integrations - where its benchmarks genuinely lead the field.
The decision turns on two questions: do you need to self-host or fine-tune, and is your primary use case text-heavy or multimodal? If self-hosting matters, Muse Spark is a non-starter. If multimodal is central to your product and you're building inside Meta's ecosystem, DeepSeek V4's text-only architecture is a real gap.
What these models actually are
Both models use Mixture-of-Experts (MoE) architecture, where each input token is routed through a small subset of specialized sub-networks rather than the full parameter set. That shared foundation is where the similarities end.
Meta Muse Spark
Muse Spark is the first model out of Meta Superintelligence Labs (MSL), a new internal division led by Alexandr Wang after Meta's $14.3 billion acquisition of Scale AI in 2025. It is natively multimodal from the ground up, handling text, images, and speech in a single model. The context window is 262,000 tokens, and the model ships with two reasoning modes: a standard Thinking mode and a deeper Contemplating mode for complex problems.
The critical fact about Muse Spark is its licensing status: it is closed and proprietary. You cannot self-host it, fine-tune it, or inspect the weights. For our full breakdown of the launch and what it means for Llama developers, see our Muse Spark launch explainer.
Key specs at a glance:
- Context window: 262K tokens
- Modalities: Text, image, and speech (native)
- Reasoning modes: Thinking and Contemplating
- License: Proprietary (closed weights)
- Access: Free on meta.ai, API pricing not publicly announced as of June 2026
- Intelligence Index (Artificial Analysis v4.0): 52
DeepSeek V4
DeepSeek V4 launched April 24, 2026, in preview under an MIT license. It comes in two production variants with meaningfully different cost and capability profiles.
| Variant | Total Parameters | Active Parameters | Context Window | License |
|---|---|---|---|---|
| V4-Flash | 284B | 13B | 1M tokens | MIT |
| V4-Pro | 1.6T | 49B | 1M tokens | MIT |
The active parameter count is the number that matters for inference cost and speed. V4-Pro has 1.6 trillion total parameters, but because MoE routes each token through only 49 billion of them, serving the model doesn't require 1.6T-scale compute on every call.
DeepSeek V4 also merges the separate R1 reasoning line into a single model. You toggle thinking on or off per request rather than switching between two model versions. The API is OpenAI-compatible, meaning existing integrations built against the OpenAI SDK require minimal changes to switch over.
Key specs at a glance:
- Context window: 1M tokens (both variants)
- Modalities: Text only
- Reasoning: Integrated thinking toggle (replaces the separate R1 line)
- License: MIT (full open weights on Hugging Face)
- API pricing (V4-Flash): $0.14/M input, $0.28/M output
- API pricing (V4-Pro): $0.145/M input, $3.48/M output
Note: The April 24 V4 release is labeled a preview. Specifications, pricing, and behavior may change at general availability, expected later in 2026. Legacy V3 API aliases currently route to V4-Flash; the migration deadline is July 24, 2026.
The architecture that drives the cost gap
Both models use MoE, but the way DeepSeek implemented it for V4 is the reason its pricing looks so aggressive.
Standard Dense Model
┌─────────────────────────────────┐
│ Input token │
│ │ │
│ All N parameters computed │
│ (full model per token) │
└─────────────────────────────────┘
DeepSeek V4-Pro (MoE)
┌─────────────────────────────────┐
│ Input token │
│ │ │
│ Router selects K experts │
│ (49B active / 1.6T total) │
│ │ │
│ Only K experts compute │
│ (fraction of full model) │
└─────────────────────────────────┘DeepSeek V4's Sparse Attention system (DSA) combines two compression techniques - Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) - to serve the 1M token context window without passing the cost of a 1M-context retrieval to the caller on every request. Cache-hit pricing makes repeated long prompts (RAG context blocks, long system prompts) cheaper over time.
The practical effect: processing 100M input tokens and 20M output tokens per month on V4-Pro costs roughly $22.60. The same workload on Claude Opus 4.7 or GPT-5.5 runs an order of magnitude higher. That delta isn't a rounding error in a production budget - it changes which products are viable to build.
Benchmark results: keeping Meta's self-reporting separate
Benchmark credibility note: Meta confirmed benchmark manipulation in the Llama 4 launch (Yann LeCun acknowledged this publicly in January 2026). Treat all self-reported Muse Spark scores with appropriate skepticism. The figures below separate Meta's self-reported numbers from independent evaluations where possible.
Where Muse Spark leads (independently verified or from third parties)
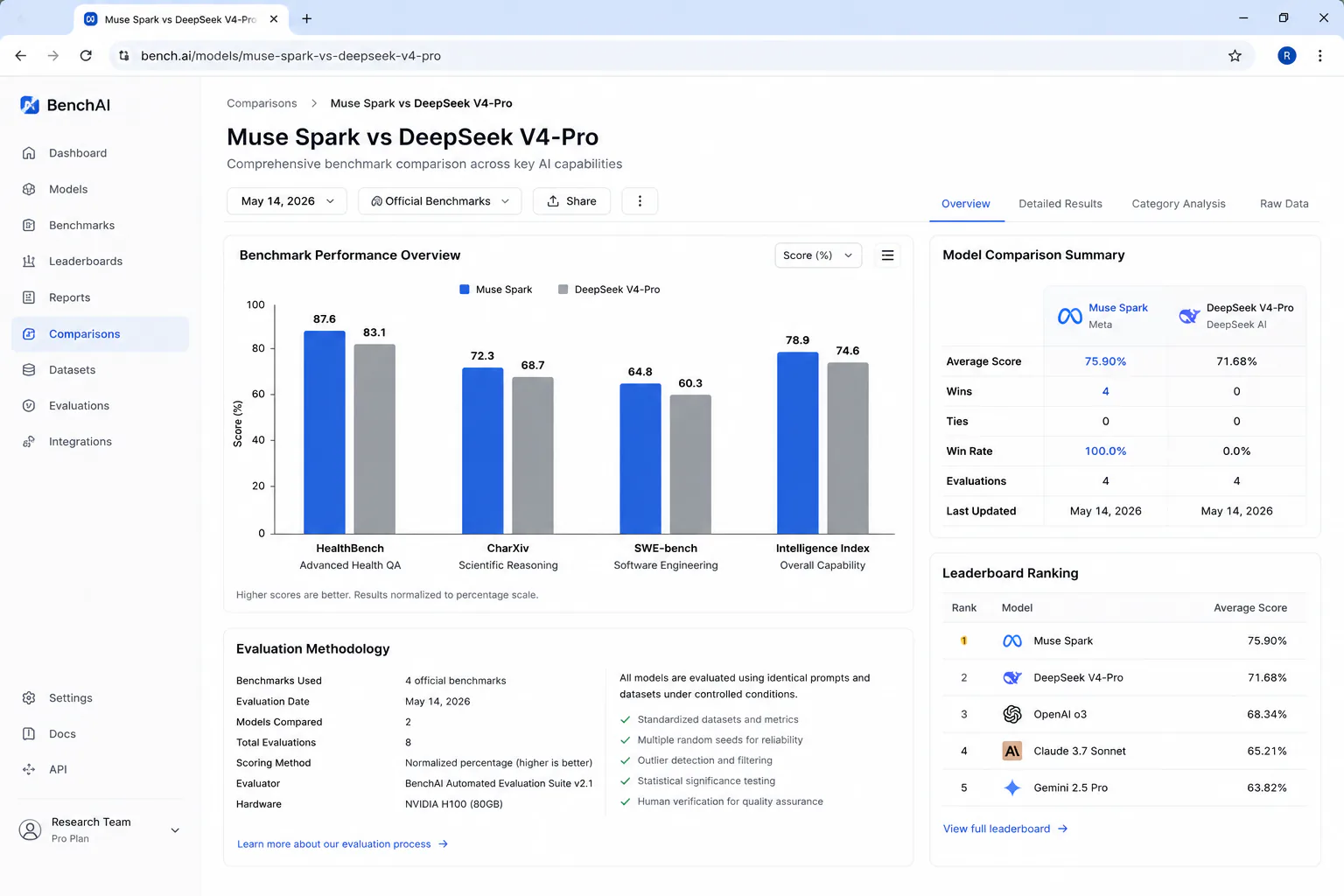
- HealthBench Hard: 42.8 - the highest score of any model, ahead of GPT-5.4 (40.1) and Gemini 3.1 Pro (20.6). Developed with input from more than 1,000 physicians.
- CharXiv Reasoning (visual figure understanding): 86.4 - leading Claude Opus 4.6 (65.3) and GPT-5.4 (82.8). Relevant for scientific and financial chart interpretation.
- Token efficiency - Muse Spark used 2.7x fewer output tokens than Claude Opus 4.6 across the Intelligence Index evaluation suite.
- Intelligence Index overall: 52 - 4th in the field, behind GPT-5.4 (57), Gemini 3.1 Pro Preview (57), and Claude Opus 4.6 (53).
Where DeepSeek V4 leads
- SWE-bench Verified (V4-Pro-Max): 80.6% - Note: this figure comes from llm-stats, not the canonical Scale SEAL leaderboard, which lists no V4 entry as of June 2026. It trails Claude Opus 4.8 (88.6%) and Fable 5 (95%).
- LiveCodeBench Pass@1 (V4-Pro-Max): 93.5, with a Codeforces rating of 3206. Coding strength is a clear V4-Pro edge over Muse Spark.
- Coding Index: V4-Pro beats Muse Spark's 47.5 - Meta explicitly acknowledges coding as a current gap; Muse Spark trails Claude Sonnet 4.6 and GPT-5.4 on coding benchmarks.
The honest read: Muse Spark is the better model for health and visual reasoning. DeepSeek V4-Pro is the better model for code. Neither beats the current frontier leaders (GPT-5.4, Claude Opus 4.7) on general intelligence.
Pricing: where the real decision lives
This is where the comparison gets interesting for anyone building a production system.
| Dimension | Muse Spark | DeepSeek V4-Flash | DeepSeek V4-Pro |
|---|---|---|---|
| Input price (per 1M tokens) | Not yet published (free on meta.ai) | $0.14 | $0.145 |
| Output price (per 1M tokens) | Not yet published | $0.28 | $3.48 |
| Context window | 262K | 1M | 1M |
| Self-hostable | No | Yes (consumer GPU feasible) | Limited (cluster-scale) |
| Fine-tuning | No | Yes | Yes |
| License | Proprietary | MIT | MIT |
| OpenAI-compatible API | No | Yes | Yes |
Muse Spark's API pricing hasn't been publicly announced. On meta.ai, it's free for consumer use. For enterprise API access, Meta has not published a rate card as of June 2026. Any production budget comparison should be flagged with that uncertainty - verify current pricing at ai.meta.com before committing.
DeepSeek V4-Flash at $0.28/M output is cheaper than GPT-5.4 Nano on output tokens. For batch workloads - document classification, extraction, summarization - the cost floor it sets makes previously marginal products economically viable.
Head-to-head comparison
| Feature | Muse Spark | DeepSeek V4-Flash | DeepSeek V4-Pro |
|---|---|---|---|
| License | Proprietary | MIT | MIT |
| Context window | 262K | 1M | 1M |
| Multimodal (text/image/speech) | Yes | No | No |
| Fine-tuning available | No | Yes | Yes |
| Self-hostable | No | Yes | Limited |
| OpenAI-compatible API | No | Yes | Yes |
| Integrated reasoning mode | Yes (Contemplating) | Yes (thinking toggle) | Yes (thinking toggle) |
| HealthBench Hard | 42.8 (best in class) | N/A | N/A |
| CharXiv Reasoning | 86.4 (best in class) | N/A | N/A |
| SWE-bench Verified | Below Sonnet 4.6 | N/A | 80.6% (V4-Pro-Max) |
| Intelligence Index | 52 (4th overall) | Mid-range | Near-frontier |
| Hardware dependency | US cloud | Huawei (self-host option) | Huawei (self-host option) |
| Benchmark trust | Low (Llama 4 history) | Moderate (preview) | Moderate (preview) |
Where each model actually wins
Muse Spark is the right call when:
- Healthcare is your primary use case. The HealthBench Hard score of 42.8 is not marginal - it's 6.7 points ahead of GPT-5.4. If you're building clinical decision support, patient-facing health assistants, or medical Q&A, this lead matters in ways that are hard to close elsewhere.
- You're building on Meta's platforms. Muse Spark rolls out by default across WhatsApp, Instagram, Facebook, and Messenger to more than 3 billion users. If your product integrates with Meta's social graph, Muse Spark is the path of least friction.
- Visual figure understanding is central. The 86.4 CharXiv Reasoning score makes Muse Spark the strongest publicly available model for interpreting scientific figures, financial charts, and complex data visualizations. Document processing pipelines with a heavy visual component benefit from this lead.
- Multimodal input is non-negotiable. For applications that need simultaneous text, image, and speech processing without building separate pipelines for each modality, Muse Spark's native architecture simplifies the integration significantly.
DeepSeek V4 is the right call when:
- Cost at scale determines what you can build. High-volume batch workloads - extraction, classification, summarization, RAG pipelines - at V4-Flash prices are economically viable at scales where frontier API pricing is not. Run the actual token math for your workload before deciding.
- Data residency or compliance requires self-hosting. MIT license means you can download the weights, run V4-Flash on a single well-provisioned GPU server, and never send a token to an external API. Financial services, healthcare outside the US, and government organizations frequently have this requirement.
- Coding tasks are central. V4-Pro's coding benchmarks clearly outperform Muse Spark. For agentic coding workflows, code review, or repository-scale refactoring, V4-Pro is the stronger tool at the price. See how V4 compares in production CI/CD pipelines in our guardian agents tutorial.
- Long-document analysis is in scope. Processing an entire legal contract, codebase, or year's worth of email in a single call requires the 1M token context that V4 provides and Muse Spark cannot match.
- You're migrating from OpenAI. The OpenAI-compatible API means existing integrations built against the OpenAI SDK need minimal code changes to route to V4. Migration friction is low.
- Your team fine-tunes or adapts models. Domain-specific fine-tuning (legal, scientific, code review) is only possible with open weights. Muse Spark cannot be fine-tuned.
The hybrid that's emerging in practice
A growing pattern in production environments: route by task type. V4-Flash handles classification, extraction, and first-pass drafts. V4-Pro handles multi-step reasoning and agentic tasks. Muse Spark or a frontier closed model handles queries requiring image input or health-sensitive responses. Teams using this tiered routing pattern report cost reductions of 60-70% compared to sending all traffic to a single frontier model.
This also separates the geopolitical risk. If DeepSeek's Chinese cloud infrastructure is a data privacy concern for any workload, that workload goes to a different model. The architecture doesn't force an all-or-nothing commitment to either model.
The open-source question that matters for your stack
This comparison sits inside a larger story. Meta built the Llama franchise on open weights and became the loudest advocate for open-source AI. Muse Spark is a complete reversal. Meta's statement that it "hopes to open-source future versions" comes with no timeline and no commitment.
The vacuum Meta left in the open-weight space is being filled by DeepSeek V4, Qwen 3.6, Kimi K2.6, and Gemma 4 - none of them from Western labs. The developer community that rallied around Llama has largely migrated to these alternatives. If your stack relies on open weights for compliance, customization, or cost, the Muse Spark announcement does not help you.
For teams evaluating agent protocols alongside model selection, the open-source stack question is directly related to how you structure tool calling and inter-agent communication. Our comparison of MCP vs A2A protocol for AI agent stacks covers how these architectural decisions interact with model selection.
DeepSeek V4 running on Huawei chips also carries a specific implication: US chip export restrictions designed to constrain Chinese AI development appear to have accelerated hardware independence instead. Each generation of DeepSeek trained on domestic silicon reduces supply chain dependency. For non-US organizations, this is a feature, not a concern.
Which one should you choose?
For most developers building production systems in mid-2026, DeepSeek V4-Pro is the default recommendation. The MIT license, 1M context, OpenAI-compatible API, and pricing that makes high-volume workloads viable combine into a practical advantage that Muse Spark's benchmark wins don't consistently overcome.
Muse Spark earns a clear first-choice position in two specific contexts: healthcare applications (where its HealthBench Hard score is a genuine performance lead) and products built directly on Meta's social platforms. Outside those, the proprietary status and unannounced API pricing are hard to plan around.
The hybrid routing approach is worth taking seriously regardless. The cost structure of V4-Flash for routine tasks versus a frontier model for complex or multimodal ones isn't an architectural compromise - it's a rational response to the way pricing has fractured across the market.
Frequently asked questions
DeepSeek V4-Flash and V4-Pro are available through DeepSeek's API at $0.14/M input and $0.28/M output (Flash) and $0.145/M input and $3.48/M output (Pro) as of June 2026. The weights are downloadable for free from Hugging Face under an MIT license for self-hosting. There is no free API tier for production use, though the pricing is significantly lower than comparable closed models.
No. Muse Spark is closed-source and proprietary - Meta has not released the weights publicly. You can access it free on meta.ai for consumer use, and Meta offers an API for developers, but the model cannot be self-hosted, fine-tuned, or quantized. If self-hosting is a requirement for your use case, Muse Spark is not an option.
It depends on your data residency requirements. If you use DeepSeek's cloud API, traffic routes through Chinese infrastructure - a non-starter for regulated industries in many jurisdictions (GDPR, HIPAA, US government). If you self-host the V4 weights on your own infrastructure using the MIT license, data stays within your control. Enterprises with strict data policies should self-host or use a compliant cloud provider offering V4 hosting.
Muse Spark scores 52 on the Artificial Analysis Intelligence Index, placing it 4th behind GPT-5.4 (57), Gemini 3.1 Pro Preview (57), and Claude Opus 4.6 (53). Its clearest leads are in HealthBench Hard (42.8, best in class) and CharXiv visual reasoning (86.4, best in class). On coding, Muse Spark trails Claude Sonnet 4.6 and GPT-5.4, which Meta has publicly acknowledged as a current gap. Treat self-reported Muse Spark scores cautiously given the confirmed Llama 4 benchmark controversy.
DeepSeek has not announced a multimodal V4 variant as of June 2026, but it is widely anticipated as the next major capability gap to close. The current April 2026 release is a preview; a general availability version with additional capabilities is expected later in 2026. If multimodal is critical to your use case today, V4 is not the right choice - Muse Spark, Gemini 3.1, or GPT-5.4 are all viable alternatives.