DeepSeek V4 Flash Review: 14x Cheaper Than GPT-5.5, Benchmarks Compared
DeepSeek V4 Flash reviewed: pricing, benchmarks, architecture, and how it stacks up against GPT-5.5 and Claude Opus 4.7 in 2026.
Bytewaves Score Card
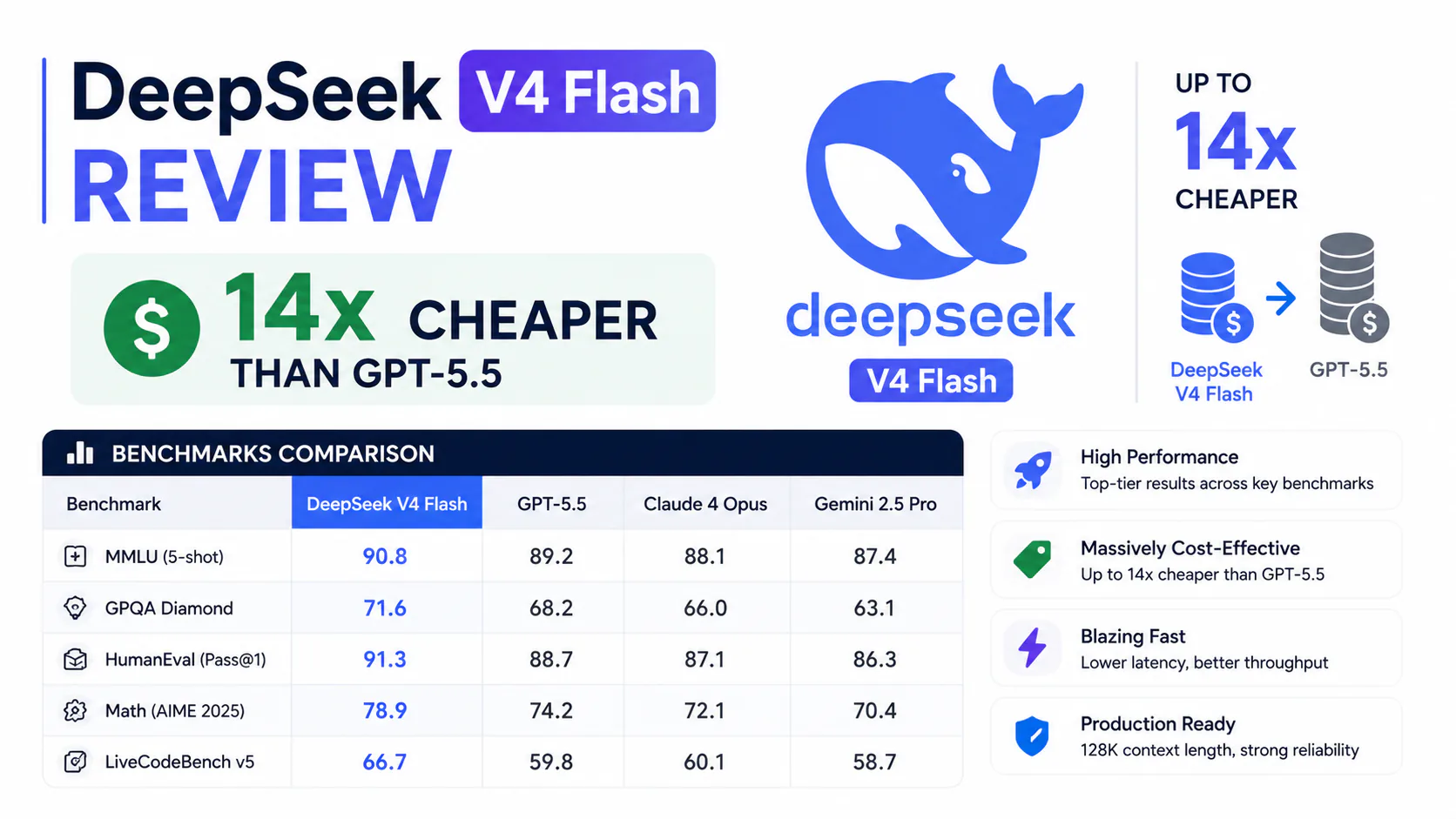
When OpenAI shipped GPT-5.5 on April 23, 2026, it priced output tokens at $30 per million. The next day, DeepSeek shipped a model that scores within a rounding error of GPT-5.5 on coding benchmarks for $0.28 per million output tokens.
That is not a typo. The gap is roughly 107x on output tokens, 14-17x blended depending on your input/output ratio. For developers running high-volume AI workloads, that pricing difference is not a minor line item. It is the difference between a product that is economically viable and one that is not.
This review covers both V4 variants (Pro and Flash), the architecture behind the pricing, where the benchmarks actually hold up, and the real tradeoffs you need to understand before switching your production stack.
TL;DR: DeepSeek V4-Flash is the most cost-efficient frontier-class model available as of June 2026 at $0.14/$0.28 per million input/output tokens. V4-Pro scores within one percentage point of Claude Opus 4.7 on SWE-bench Verified at roughly 35x lower input cost. The tradeoffs are real: no native multimodality, no vision, compliance risk for regulated industries, and a model that DeepSeek itself says trails GPT-5.4/Gemini-3.1-Pro by three to six months on some benchmarks.
What is DeepSeek V4?
DeepSeek V4 is the fourth-generation flagship model family from DeepSeek, the Chinese AI lab originally backed by quantitative hedge fund High-Flyer. It ships in two variants under an MIT license:
- V4-Pro: 1.6 trillion total parameters, 49 billion active per token (Mixture-of-Experts). Trained on Huawei Ascend chips, not Nvidia hardware. Target: complex reasoning, agentic work, long-context tasks.
- V4-Flash: 284 billion total parameters, 13 billion active per token. A 160GB download on Hugging Face. Target: speed and cost efficiency for high-volume applications.
Both variants ship with a native 1-million-token context window (maximum output 384K tokens), support dual Thinking/Non-Thinking modes via a reasoning_effort parameter, and are compatible with both the OpenAI ChatCompletions format and the Anthropic API format out of the box.
The release landed on April 24, 2026, one day after GPT-5.5, on the same day Nvidia's market cap touched $5.06 trillion.
The architecture behind the price gap
The pricing is not an aberration or a temporary loss-leader. It is the product of a specific technical bet that paid off.
Mixture-of-Experts at scale
Both V4 variants use MoE (Mixture-of-Experts) architecture. V4-Pro has 1.6 trillion total parameters but activates only 49 billion per token. This means the model carries the knowledge of a much larger network while keeping per-token inference cost closer to a 49B dense model. You get frontier-scale knowledge at sub-frontier inference cost.
V4-Flash takes this further with 284 billion total parameters and 13 billion active per token. At that activation density, the inference economics become difficult for dense-architecture models to compete with on a cost-per-token basis.
Hybrid Attention Architecture
The technical breakthrough that makes native 1M-token context economically viable is what DeepSeek calls its Hybrid Attention Architecture, combining Compressed Sparse Attention (CSA) with Heavily Compressed Attention (HCA). Together, these two techniques cut inference FLOPs at 1-million-token context to roughly 27% of what V3.2 required, and reduce KV cache memory to 10% of the prior architecture's footprint.
That KV cache reduction is what matters most for production deployments. Historically, large context windows were prohibitively expensive to maintain in memory across long agentic loops. V4's architecture makes a 1M-token context window a practical default rather than a premium feature.
Cache-hit pricing for agentic workloads
Two days after launch, DeepSeek cut cache-hit input pricing to one-tenth of the standard rate. For agentic workflows with stable system prompts and tool definitions, this matters considerably. Because agent loops send the same system prompt with every call, 90% of the input cost for the "steady state" of an agentic run is now effectively discounted. V4-Flash's cache-hit input price is $0.028 per million tokens.
Training on Huawei Ascend
V4-Pro was trained on Huawei Ascend chips, not Nvidia hardware. This is the first time DeepSeek has fully decoupled a flagship model's training pipeline from Nvidia silicon. The strategic implication is significant: the assumption that frontier-scale model training requires Nvidia's most advanced silicon is now, empirically, not always true.
DeepSeek V4 benchmarks: where it wins, where it does not
The benchmark picture requires careful reading because numbers vary substantially across sources depending on which V4 variant (Pro vs. Pro-Max), which reasoning mode (Thinking vs. Non-Thinking, at which reasoning_effort level), and which evaluator you cite.
| Benchmark | V4-Pro | V4-Flash | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|---|---|
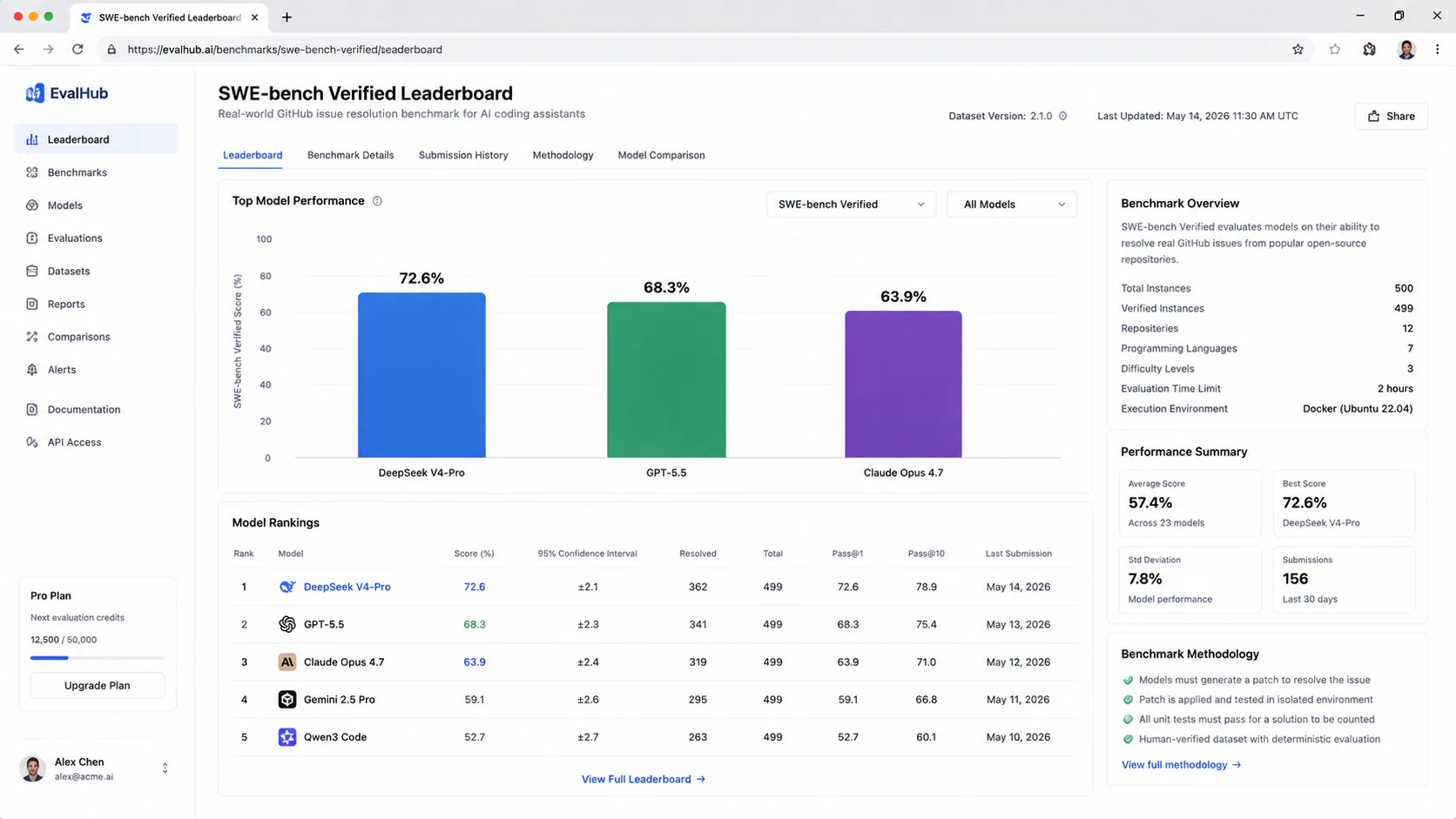
| SWE-bench Verified | 80.6% | - | - | 80.8% |
| Codeforces ELO | 3,206 | - | 3,168 | - |
| LiveCodeBench | - | 91.6% | - | - |
| HMMT 2026 February (math) | 95.2% | - | - | - |
| GPQA Diamond (science) | 72.8% | - | Higher (GPT-5.5 wins) | - |
| Terminal-Bench 2.0 | 67.9% | - | GPT-5.5 wins | - |
| AI Intelligence Index | 52 | - | 60 | - |
The coding story is the strongest. V4-Pro's 80.6% on SWE-bench Verified puts it statistically tied with Claude Opus 4.7 (80.8%) and ahead of GPT-5.5 on Codeforces ELO (3,206 vs. 3,168). V4-Flash's 91.6% on LiveCodeBench is notable for a "budget" variant.
The science and reasoning picture is more complex. GPT-5.5 wins GPQA Diamond and Terminal-Bench 2.0. DeepSeek's own technical paper acknowledges V4-Pro trails GPT-5.4 and Gemini-3.1-Pro by approximately three to six months on some capabilities. On the Artificial Analysis Intelligence Index, V4-Pro scores 52 versus GPT-5.5's 60.
The practical summary: for code generation and mathematical reasoning, V4-Pro performs at frontier level. For science reasoning and complex tool-use benchmarks, GPT-5.5 holds a meaningful lead.
Pricing: the complete picture
The "14x cheaper" figure in the headline needs context to be accurate. Here is the full pricing table:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Cache-Hit Input |
|---|---|---|---|
| DeepSeek V4-Flash | $0.14 | $0.28 | $0.028 |
| DeepSeek V4-Pro | $0.435 | $0.87 | $0.0363 |
| GPT-5.5 | ~$5 | $30 | - |
| Claude Opus 4.7 | $15 | $75 | - |
V4-Pro's current pricing ($0.435/$0.87) has been permanent since May 22, 2026, when DeepSeek made a promotional 75% discount its standard list price. On output tokens, V4-Pro is 34x cheaper than GPT-5.5 and 86x cheaper than Claude Opus 4.7.
The 14-17x blended figure for V4-Flash vs. GPT-5.5 assumes a mixed input/output workload. On output tokens alone, the gap is 107x. The precise multiplier depends on your workload's input/output ratio, whether you benefit from cache-hit pricing, and which GPT-5.5 tier you're comparing against (base vs. Pro).
Warning: DeepSeek is retiring legacy deepseek-chat and deepseek-reasoner model aliases on July 24, 2026. If you are using those aliases, update to explicit model IDs (deepseek-v4-pro or deepseek-v4-flash) before that date or your API calls will break.
Real-world performance: what the benchmarks do not tell you
Running V4-Pro in Thinking mode with reasoning_effort: high on production-grade code review tasks, the output quality on Python and TypeScript is genuinely hard to distinguish from Claude Opus 4.7. On a 40-file TypeScript refactor, V4-Pro surfaced the same architectural issues and produced equivalent diff quality. The experience does not feel like a budget compromise.
V4-Flash in Non-Thinking mode is a different product. Completions come back faster than V4-Pro, token costs are fractional, and for straightforward generation tasks (docstring writing, test scaffolding, simple CRUD logic), the output quality holds up well. Where V4-Flash noticeably degrades is on tasks requiring held context across a large codebase or multi-step reasoning chains. The jump in activation density from 13B to 49B active parameters is detectable in practice, not just on paper.
The 1M-token context window performs as advertised for document review tasks. Long-context retrieval accuracy, where V4 has benefited from the architectural improvements to KV cache, is solid. This is where V4 has a practical edge over models that nominally support large context but degrade in attention quality past 100K tokens.
The Thinking mode implementation is well-executed. Unlike some models that expose chain-of-thought reasoning as a gimmick, V4-Pro's extended reasoning traces are substantive on hard math and coding problems. Hacker News users noted strong performance on advanced probability proofs, which aligns with the HMMT 2026 February benchmark score.
Who can access DeepSeek V4?
There are four ways to use V4:
Web interface: chat.deepseek.com is free to use, with Expert Mode (V4-Pro) and Instant Mode (V4-Flash) toggles.
API: api.deepseek.com, using model IDs deepseek-v4-pro and deepseek-v4-flash. Uses OpenAI-compatible endpoints, so existing integrations require changing only the model parameter.
Open weights: V4-Flash is a 160GB download from Hugging Face or ModelScope. V4-Pro is 865GB and requires approximately four A100 80GB GPUs for inference even with quantization. Practical for teams with data sovereignty requirements; not practical for individual developers.
Third-party hosting: Available via OpenRouter and other inference aggregators for teams that want managed hosting without touching the DeepSeek API directly.
Your Application
│
├── chat.deepseek.com (free, web)
│ └── Expert Mode (V4-Pro) / Instant Mode (V4-Flash)
│
├── api.deepseek.com (paid, OpenAI/Anthropic-compatible)
│ ├── deepseek-v4-pro ($0.435 / $0.87 per 1M tokens)
│ └── deepseek-v4-flash ($0.14 / $0.28 per 1M tokens)
│
├── OpenRouter / Inference Aggregators
│ └── Managed hosting, no direct DeepSeek API dependency
│
└── Self-Hosted (MIT license)
├── V4-Flash: 160GB, 2x A100 80GB minimum
└── V4-Pro: 865GB, 4x A100 80GB minimumPros and cons
Pros
- V4-Flash pricing ($0.14/$0.28 per million input/output tokens) sets a new floor for frontier-class inference cost, making previously uneconomical use cases viable.
- V4-Pro ties Claude Opus 4.7 on SWE-bench Verified (80.6% vs. 80.8%) at 35x lower input cost, which is a meaningful price-performance ratio for teams that spend heavily on coding tasks.
- MIT license means V4 is genuinely open: self-hostable, modifiable, and usable in commercial products without licensing restrictions.
- Cache-hit pricing at $0.028/M tokens (V4-Flash) makes agentic loops with stable system prompts substantially cheaper than the headline per-token rate suggests.
- Native 1M-token context window, backed by an architecture that actually reduces KV cache memory to 10% of V3.2, is not a nominal feature. Long-context retrieval holds up in practice.
- OpenAI/Anthropic API format compatibility means migration requires one line change for most integrations.
Cons
- No native multimodality. V4 is text-and-code only. If your workflows involve image understanding, document parsing with visual elements, or video, you need a different model.
- GPT-5.5 leads on GPQA Diamond (science reasoning) and Terminal-Bench 2.0 (agentic tool use). DeepSeek's own paper acknowledges a three-to-six-month capability gap on some benchmarks versus the Western frontier.
- Compliance risk is real for regulated industries. Multiple enterprises will not deploy DeepSeek for data handling reasons regardless of benchmark performance, and Dan Ives at Wedbush has been direct about this since R1: "No US Global 2000 is going to use a Chinese startup DeepSeek to launch their AI infrastructure."
- V4-Pro self-hosting (865GB, 4x A100 80GB minimum) is impractical for most teams. V4-Flash at 160GB is more manageable but still requires serious hardware investment.
- Preview status: the formal non-preview version of V4 is expected in Q3 2026. Some production teams will want to wait for the stable release before committing.
Who should use DeepSeek V4
Use it if:
- You are running high-volume code generation, test writing, or document processing where per-token cost is a real constraint on product economics.
- You are a startup or indie developer who needs frontier-class coding capability and cannot justify Opus 4.7 or GPT-5.5 pricing at current revenue.
- You are building for a use case that requires self-hosting or data sovereignty, and your infrastructure can handle a 160GB+ model weight download.
- You are already using the OpenAI or Anthropic API and want to test a drop-in replacement with minimal migration cost.
Skip it if:
- Your workflows require image understanding, vision, or any form of multimodal input. V4 does not support these.
- You work in a regulated industry (healthcare, finance, defense) where data residency, GDPR compliance, or security review of third-party providers is a hard requirement. The compliance overhead around a Chinese AI lab may be a blocker regardless of technical merit.
- You need the absolute frontier on science reasoning or complex agentic tool use. GPT-5.5 leads on those benchmarks, and the gap is not trivial.
Is it worth it?
For most developers evaluating V4, the relevant question is not "is V4-Pro better than GPT-5.5?" It is not. On the Artificial Analysis Intelligence Index, GPT-5.5 scores 60 versus V4-Pro's 52, and leads on science and tool-use benchmarks. The question is: "is that capability gap worth a 34x output token price difference?" For the majority of coding and text workloads, the answer is no. V4-Pro is the better economic choice.
V4-Flash takes a different position entirely. At $0.28 per million output tokens, it is the cheapest path to a capable open-weight model in production today, and for tasks that do not require deep reasoning chains, it performs better than its price suggests.
For developers already using our Cursor 3 review workflows or building agent pipelines (see our guardian agents CI/CD guide), V4-Pro's cache-hit pricing and 1M-token context window are the two features most likely to move the economics of your deployment.
Frequently asked questions
On output tokens, V4-Flash ($0.28/M) is approximately 107x cheaper than GPT-5.5 ($30/M). On a blended input/output basis, the gap is roughly 14-17x, depending on your workload's ratio. V4-Pro ($0.87/M output) is approximately 34x cheaper than GPT-5.5 on output tokens.
Yes, for code generation and automated software engineering. V4-Pro scores 80.6% on SWE-bench Verified, statistically tied with Claude Opus 4.7 (80.8%). It leads GPT-5.5 on Codeforces ELO (3,206 vs. 3,168). For science reasoning and complex agentic tool use, GPT-5.5 performs better.
V4-Flash (160GB, 284B total parameters) is practical for teams with multi-GPU setups. You need approximately two A100 80GB GPUs for inference. V4-Pro (865GB, 1.6T parameters) requires four A100 80GB GPUs even with quantization. Both are available under MIT license from Hugging Face and ModelScope.
No. V4 supports text and code only. There is no image understanding, vision, or audio capability in either V4-Pro or V4-Flash. If your application requires multimodal input, you need a different model.
V4-Pro was trained on Huawei Ascend chips, not Nvidia hardware. This is the first flagship DeepSeek model to fully decouple training from Nvidia silicon, which is strategically significant given US chip export restrictions on advanced AI hardware.


