DeepSeek V4 Review: The Free Model Challenging Frontier AI
DeepSeek V4 reviewed in 2026: benchmarks, pricing, MoE architecture, real-world use cases, privacy risks, and who should actually switch from GPT-5.5 or Claude.

Bytewaves Score Card
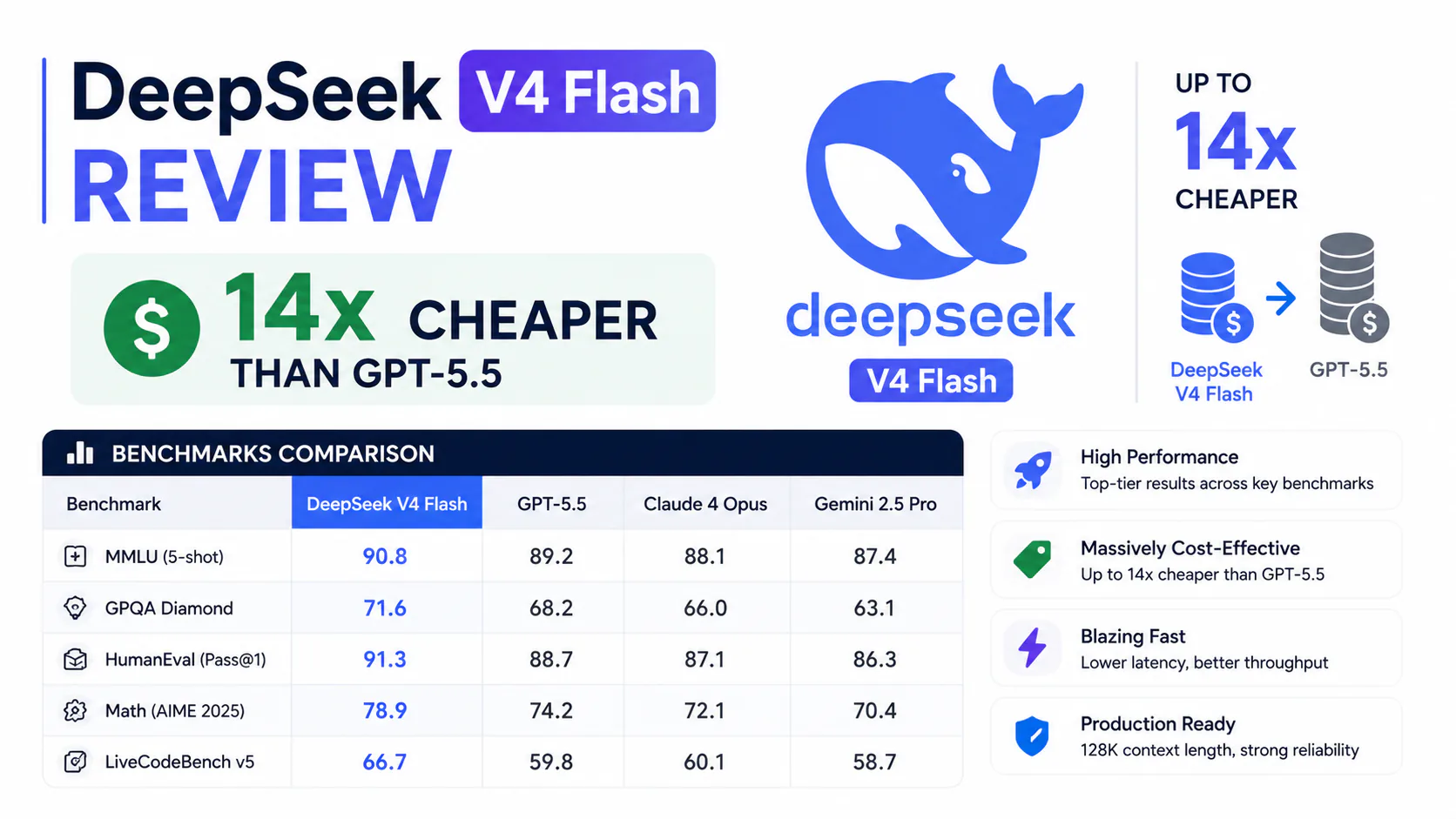
DeepSeek just made permanent what everyone assumed was a temporary discount. On May 22, 2026, the Chinese AI lab announced that V4-Pro's 75% price cut is its actual list price, not a promotional event. At $0.87 per million output tokens, it is now roughly 34 times cheaper than Claude Opus 4.7 and about 34 times cheaper than GPT-5.5 on output.
That number demands an honest answer to a practical question: is this good enough to replace what you're already running?
I tested V4-Pro and V4-Flash across coding, long-context analysis, and reasoning tasks over several weeks. This review covers what the benchmarks mean in practice, where V4 genuinely falls short, and the privacy and compliance picture every production team should understand before routing traffic to DeepSeek.
TL;DR: DeepSeek V4-Pro is a serious tool for high-volume pipelines, cost-sensitive agentic workflows, and developers who want open weights without a licensing bill. It is not a full replacement for Claude Opus 4.7 or GPT-5.5 on the most demanding production tasks, and its managed API carries real privacy and compliance risks that make it unsuitable for regulated-industry workloads.
What Is DeepSeek V4?
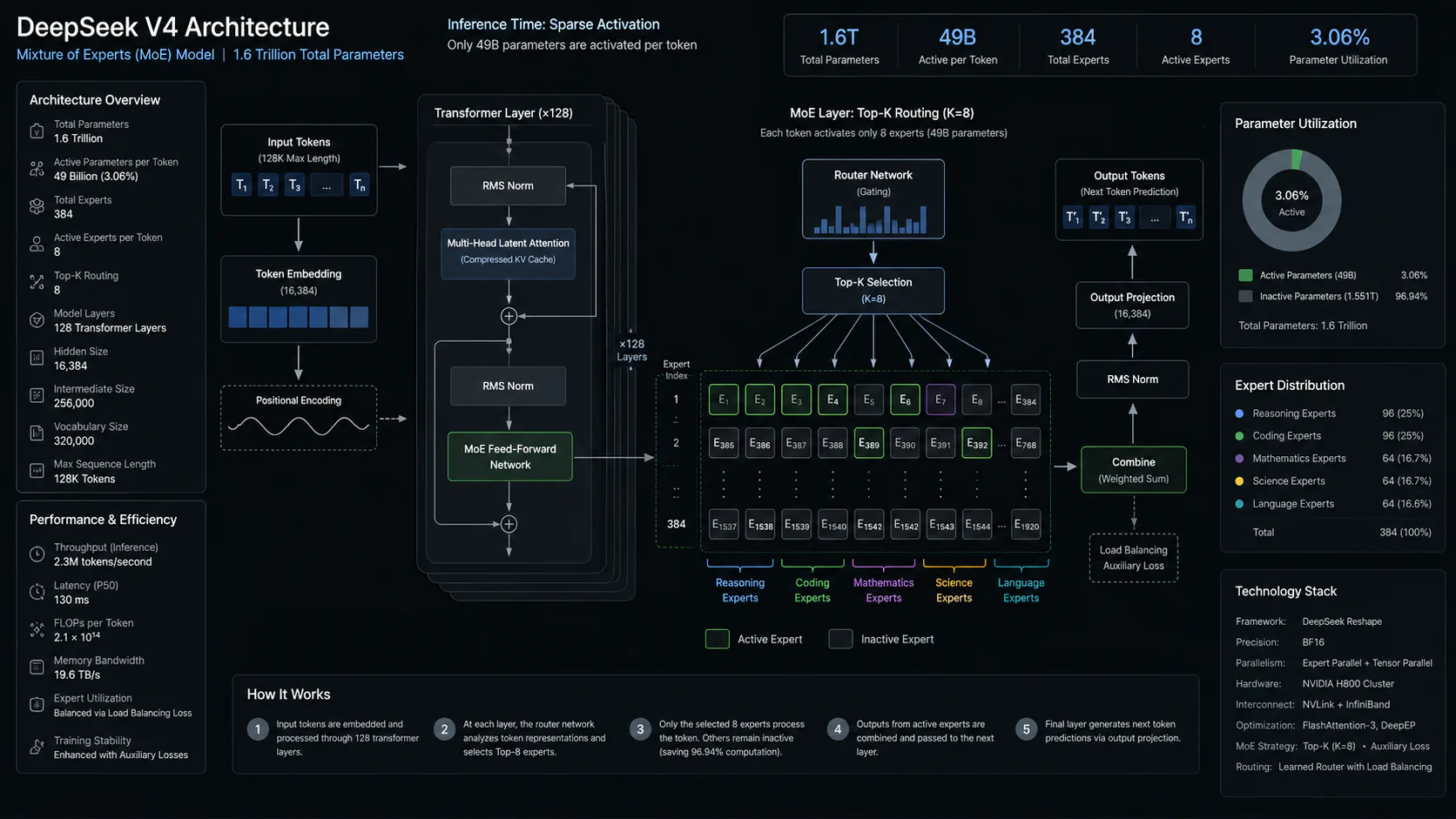
DeepSeek V4 is the fourth-generation flagship model from Hangzhou-based AI lab DeepSeek, released as a preview on April 24, 2026. It ships in two variants: V4-Pro (1.6 trillion total parameters, 49B active per token) and V4-Flash (284B total parameters, 13B active per token). Both are available via API, through the free web and mobile chat interface, and as open weights under the MIT license on Hugging Face.
The release landed the same day as OpenAI's GPT-5.5 launch. That timing was not accidental.
V4 follows the arc that started with DeepSeek R1 in January 2025, when a claimed $5.6 million training budget wiped roughly $1 trillion from US tech stocks in a single day. V4 continues the same thesis: near-frontier AI performance at prices that structurally undercut US competitors, with open weights that let you bypass the managed API entirely.
DeepSeek V4 Pro vs. Flash: Which Variant Should You Use?
The two variants are not just different sizes. They target different workloads.
V4-Pro is the model you reach for when quality matters. Its 80.6% SWE-bench Verified score (Max reasoning mode) is the highest of any open-weight model available today and roughly competitive with GPT-5.5 on coding tasks. The tradeoff is cost and latency: $0.435/M input and $0.87/M output, with Max mode adding meaningful inference time.
V4-Flash is built for throughput. At $0.14/M input and $0.28/M output, it is the cheapest capable model on the market for high-volume tasks. It handles the same 1M token context window and runs significantly faster than Pro, which makes it the natural choice for classification, extraction, summarization, and other tasks where you are running millions of tokens daily and don't need extended chain-of-thought.
A practical routing pattern emerging in production teams: V4-Flash for bulk pipeline work, V4-Pro for complex code generation, and a premium closed model (Claude Opus 4.7 or GPT-5.5) only for the longest-running agent workflows where maximum quality justifies the cost. This architecture can cut API spend by 70-90% relative to routing everything through a frontier closed model.
| Spec | V4-Pro | V4-Flash |
|---|---|---|
| Total parameters | 1.6T | 284B |
| Active per token | 49B | 13B |
| Context window | 1M tokens | 1M tokens |
| Max output tokens | 384K | 384K |
| Input price | $0.435/M | $0.14/M |
| Output price | $0.87/M | $0.28/M |
| Cache-hit input | $0.003625/M | $0.0028/M |
| Open weights | ✓ MIT | ✓ MIT |
| Self-host download | 865GB | 160GB |
How DeepSeek V4 Works: The Architecture Behind the Price
The cost advantage is not a pricing strategy. It is an engineering outcome. Understanding why matters if you are evaluating whether this pricing is sustainable.
Mixture of Experts (MoE) with Hybrid Attention
V4 uses a Mixture of Experts architecture, which means only a subset of its parameters activate for any given token. V4-Pro has 1.6T total parameters but runs 49B active per token. This allows the model to have the knowledge capacity of a much larger dense model while keeping inference compute and cost proportional to the active parameter count.
The efficiency gain on top of MoE comes from V4's Hybrid Attention Architecture, which combines two mechanisms: Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). The practical result is that V4-Pro requires only 27% of the single-token inference FLOPs and 10% of the KV cache of its predecessor (V3.2) at 1M-token context. That is what makes a 1M context window a standard included feature rather than a premium add-on.
Three Reasoning Modes
V4 gives you direct control over the latency-quality tradeoff:
- Fast: Standard response with no chain-of-thought reasoning. Fastest latency, lowest cost.
- Balanced: Moderate reasoning with some thinking tokens. The right setting for most everyday tasks.
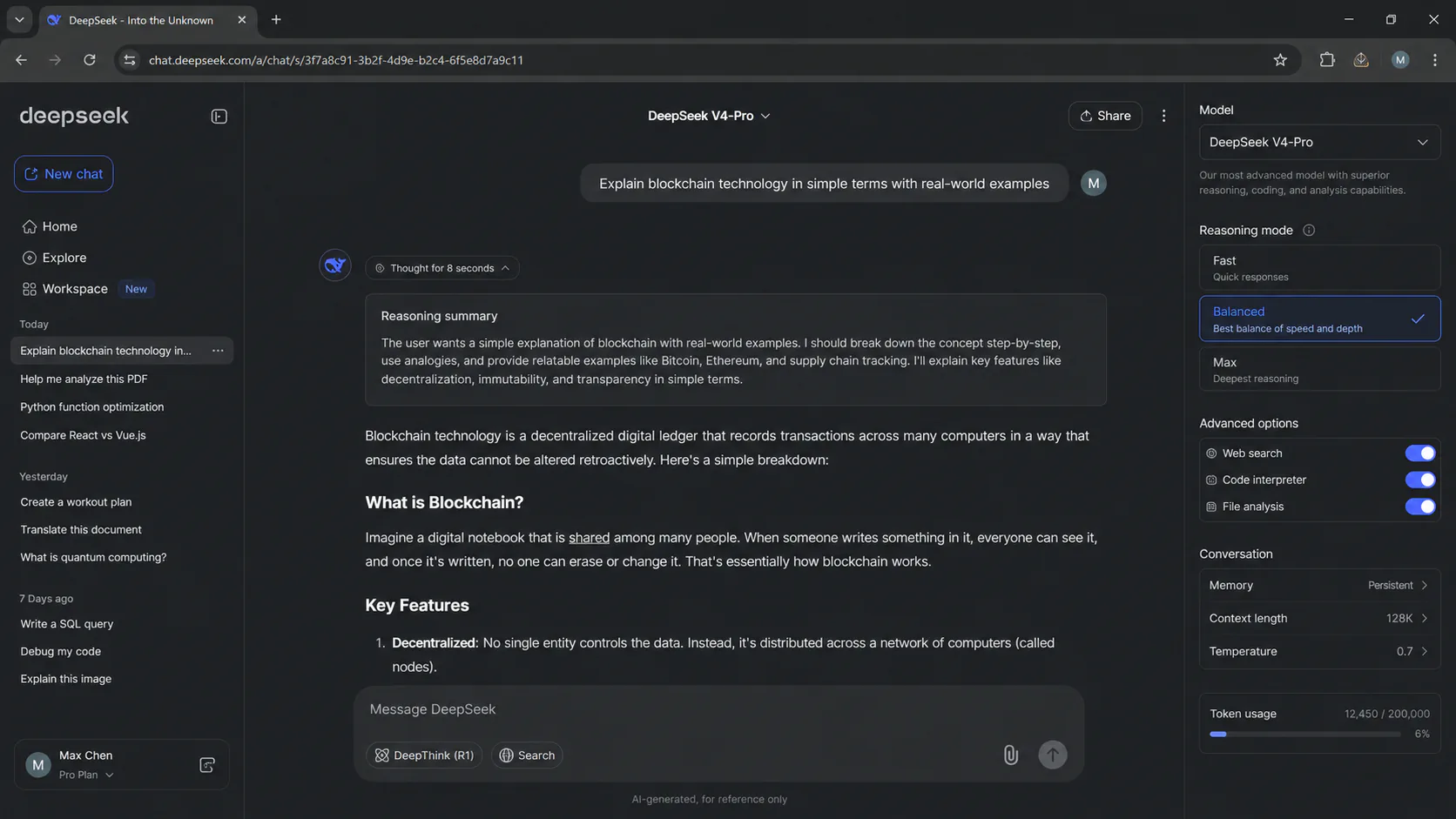
- Max: Extended chain-of-thought reasoning for hard problems. This is where V4-Pro's 80.6% SWE-bench score comes from, and where latency is highest.
One API integration note: Max mode's output includes reasoning_content fields that many popular API clients do not parse correctly. If you are integrating V4 into an existing LLM client, test Max mode responses explicitly before relying on them in production.
Huawei Ascend Chip Integration
V4 is the first major DeepSeek model explicitly engineered for Huawei's Ascend AI accelerators (specifically the Ascend 950 and 950PR), developed in collaboration with Huawei and Cambricon Technologies. DeepSeek excluded NVIDIA from early V4 access entirely.
This is the technical explanation for the permanent price cut. As Huawei Ascend 950 supernodes come online at scale in H2 2026, DeepSeek's inference cost falls further. The company has stated that V4-Pro pricing "could fall sharply" once that production capacity is fully deployed. The current floor may not be the final floor.
DeepSeek V4 Benchmarks: How Good Is It, Actually?
The headline benchmark is SWE-bench Verified: V4-Pro in Max mode scores 80.6%, making it the top open-weight model on this coding-agent benchmark as of June 2026. For context:
| Model | SWE-bench Verified | Open Weights |
|---|---|---|
| Claude Opus 4.7 | ~87.6% | No |
| DeepSeek V4-Pro (Max) | 80.6% | Yes (MIT) |
| Kimi K2.6 | ~80.2% | Yes |
| GPT-5.5 | ~78-80% (est.) | No |
| DeepSeek V4-Flash | Lower | Yes (MIT) |
V4-Pro is strong on STEM, math, and competitive programming, consistent with DeepSeek's lineage. Its GPQA Diamond score is competitive with frontier models, and it performs well on multi-step reasoning tasks in Balanced and Max modes.
Where it lags: raw world knowledge recall (GPT-5.5 leads on the HLE benchmark at 52.2), and broader multimodal tasks beyond text and code. The developmental trajectory trails state-of-the-art frontier models by approximately three to six months, a gap DeepSeek openly acknowledges in its technical report.
The honest interpretation of these numbers: for a substantial portion of professional use cases, V4-Pro in Max mode is good enough. For the most demanding production agentic workflows, the capability gap is real, and whether it matters depends entirely on your task.
Pricing: The Numbers That Changed the Market
Running 100 million output tokens per month through V4-Pro costs approximately $87. The same workload on GPT-5.5 or Claude Opus 4.7 costs roughly $2,500.
That is not a price difference. That is a budget category difference. For high-volume production pipelines, it is the difference between AI as a minor line item and AI as a major infrastructure cost.
| Model | Input $/M | Output $/M | Open Weights | Context |
|---|---|---|---|---|
| DeepSeek V4-Flash | $0.14 | $0.28 | ✓ MIT | 1M |
| DeepSeek V4-Pro | $0.435 | $0.87 | ✓ MIT | 1M |
| Gemini 3.1 Flash | $0.50 | $3.00 | No | 1M |
| GPT-5.5 | $5.00 | $30.00 | No | Variable |
| Claude Opus 4.7 | $5.00 | $25.00 | No | 200K |
The May 22, 2026 announcement that the 75% discount is permanent matters more than the numbers themselves. AI providers discount constantly. DeepSeek explicitly called this the actual market price, not a marketing event: "V4-Pro was engineered to cut the cost of long-context inference." The permanent pricing resets what "budget tier" means for the entire market.
For free access, the web and mobile interface has no query limits for registered users. V4-Flash is also the new backend for deepseek-chat and deepseek-reasoner legacy aliases, though both retire on July 24, 2026, so any existing integrations using those strings need to migrate to explicit V4 model IDs before that date.
Real-World Performance: What I Actually Tested
I ran V4-Pro and V4-Flash across three categories of tasks over several weeks. Here is what held up and what did not.
Agentic Coding Tasks
V4-Pro in Max mode handled multi-file refactoring and bug isolation reliably. On a TypeScript API codebase (~40K tokens), it correctly identified a subtle async race condition that I had deliberately planted. The reasoning trace in Max mode was genuinely useful rather than decorative, showing each hypothesis it was testing.
V4-Flash struggled on the same task. It identified the right file but misread the control flow. For agentic coding, Pro is the right tier and Max mode matters.
Both variants are explicitly supported by Claude Code and OpenClaw agentic frameworks, and the OpenAI ChatCompletions format compatibility means dropping V4-Pro into most existing LLM integrations is a few lines of config.
Long-Context Document Analysis
The 1M token context window (384K max output) with cache-hit pricing at $0.003625/M is where V4-Pro delivers the clearest cost advantage with minimal quality tradeoff. I processed a 380-page technical specification in a single prompt. The model's extraction accuracy on structured queries was strong; free-form summarization occasionally dropped details from the middle sections, a known limitation of transformer attention at extreme context lengths.
For document workflows where the task is well-defined (extract all requirements mentioning X, list all API endpoints, identify compliance clauses), V4-Pro performs at a quality level that is very difficult to justify paying 34 times more for.
Reasoning and STEM Tasks
Balanced mode performs well for most professional tasks: writing, analysis, structured output. Max mode is noticeably better for math, logic puzzles, and complex code. The difference between modes is more pronounced on V4-Pro than V4-Flash.
One recurring friction point: Max mode latency is high. For interactive applications, Balanced mode is the practical choice. Max mode is designed for batch workflows where you can wait.
How to Access DeepSeek V4
There are three ways to use V4, each with different tradeoffs on cost, privacy, and control.
Web and mobile chat: Free at chat.deepseek.com, no query limits for registered users. V4-Pro and V4-Flash are available in the mode selector. Fast mode is the default; you switch to Balanced or Max manually. Good for personal experimentation. Not appropriate for sensitive data given the privacy policy (see below).
Managed API: The V4 API is compatible with both OpenAI ChatCompletions and Anthropic API formats. Use the deepseek-v4-pro or deepseek-v4-flash model IDs (not the legacy aliases, which retire July 24). The API documentation is at api-docs.deepseek.com. Cache-hit pricing applies automatically for repeated prompt prefixes, which matters significantly for agent workflows that pass the same system prompt repeatedly.
Self-hosted open weights: V4-Pro weights (865GB) and V4-Flash weights (160GB) are on Hugging Face under the MIT license. Full-precision V4-Pro serving requires approximately 8x H100 or H200 GPUs with vLLM or SGLang for tensor-parallel inference. V4-Flash at 160GB is more accessible for teams with 2-4 high-end GPUs. Self-hosting eliminates data residency concerns entirely and removes per-token cost.
DeepSeek V4 Limitations and Risks
This is where most reviews underdeliver. V4's cost advantage is real and the benchmarks are credible. The limitations are also real, and some of them are not minor.
Capability Gap vs. Closed Frontier Models
DeepSeek's own technical report states V4 "falls marginally short of GPT-5.4 and Gemini 3.1 Pro," estimating a 3-6 month developmental lag. On the most complex multi-step agent tasks and broad world knowledge recall, that gap is measurable. Independent testing at launch found results "should be treated cautiously until independent evaluations and wider developer testing are available." For the absolute hardest production workloads, the capability gap can matter.
Privacy and Data Residency
DeepSeek's privacy policy collects user data including chat prompts, device identifiers, and network activity. All data is stored on servers in the People's Republic of China, subject to Chinese cybersecurity laws requiring cooperation with state intelligence authorities. Italy's data protection authority (Garante) has previously blocked DeepSeek over privacy concerns.
Organizations subject to GDPR, HIPAA, FedRAMP, or US government security requirements should not use the managed API for production workloads. Self-hosting on your own infrastructure solves this problem, at the cost of significant GPU investment for V4-Pro.
Political Censorship and Safety Guardrails
Users and independent testers have documented that V4 refuses to discuss topics sensitive to the Chinese government. South Korea's National Intelligence Service formally documented asymmetric content behavior, meaning the model responds differently depending on the language used. For general professional and coding tasks, this is unlikely to surface. For research applications touching politics, history, or geopolitics, it is a real and documented limitation.
On jailbreak resistance, Cisco testing found V4 more vulnerable than leading Western models. For applications where safety guardrails are a compliance requirement, this warrants evaluation before deployment.
No Enterprise SLAs
There are no enterprise support tiers, uptime SLAs, compliance certifications, or data residency guarantees comparable to what Anthropic, OpenAI, or Google offer enterprise customers. For regulated-industry deployments on the managed API, this is a blocking issue. For startups and teams that can absorb some API instability, it is a known risk rather than a dealbreaker.
API Alias Retirement Deadline
If your current integration uses deepseek-chat or deepseek-reasoner as model IDs, they map to V4-Flash now and fully retire on July 24, 2026. Migrate to explicit V4 model identifiers before that date.
Pros and Cons
Pros
- The permanently reduced pricing is a genuine market floor, not a promotion: $0.87/M output for Pro and $0.28/M for Flash are the lowest prices for frontier-class open-weight models available today.
- MIT-licensed open weights mean you can download, fine-tune, and self-host without licensing restrictions, giving full data sovereignty to teams with the GPU capacity.
- The 1M token context window is standard on both variants, enabling entire-codebase analysis and long-document workflows that would cost dramatically more with context-limited alternatives.
- Three configurable reasoning modes give you meaningful control over the latency-cost-quality tradeoff rather than a binary fast/slow choice.
- OpenAI and Anthropic API format compatibility means integrating V4 into existing stacks requires minimal code changes.
Cons
- The managed API stores all data on servers in China under Chinese cybersecurity law, making it unsuitable for regulated-industry workloads without self-hosting.
- Documented political censorship for topics sensitive to the Chinese government is a real limitation for research and general-knowledge applications.
- Full V4-Pro self-hosting requires approximately 8x H100/H200 GPUs, putting on-premises deployment out of reach for most small teams.
- No enterprise SLAs, support tiers, or compliance documentation exist, creating business continuity risk for organizations that cannot tolerate API instability.
- The
reasoning_contentfield in Max mode is not handled correctly by many popular LLM API clients, requiring testing and often custom parsing before production use.
Who Should Use DeepSeek V4
Use it if:
- You are running high-volume pipelines (classification, extraction, summarization, structured output) where cost savings of 10-34x directly affect product economics and your data does not fall under strict residency regulations.
- You need open weights with an MIT license for fine-tuning, self-hosting, or operating in an air-gapped environment, and you have the GPU infrastructure to serve V4-Flash (160GB) or V4-Pro (865GB).
- You are prototyping or experimenting with long-context AI tasks, agentic coding workflows, or multi-model routing architectures where you want a capable, cheap middle tier.
- Your workloads are STEM-heavy (math, code, structured reasoning) where V4's strongest benchmark performance overlaps with real task requirements.
Skip it if:
- Your organization is subject to GDPR, HIPAA, FedRAMP, or US government security requirements and you cannot self-host. The managed API's data residency makes this a compliance risk, not a preference.
- You need enterprise SLAs, 24/7 support, or formal compliance documentation. DeepSeek offers none of these for the managed API.
- Your application requires reliable responses on politically sensitive topics. The documented censorship behavior is a real constraint, not a theoretical concern.
- You are building production agentic workflows that require peak performance on the most complex multi-step tasks. For those workloads, the 3-6 month capability gap vs. Claude Opus 4.7 is measurable and worth paying for.
If you are evaluating how DeepSeek V4 fits into a broader agentic stack, our comparison of MCP vs. A2A protocols is relevant context for multi-model routing architecture decisions.
For teams already using AI coding tools and wondering how V4 fits into developer workflows, our Cursor 3 review covers how agent-oriented editors handle multi-model backends.
Is It Worth It?
DeepSeek V4-Pro is worth using for a clear category of workloads: high-volume, cost-sensitive pipelines where you need near-frontier coding and reasoning performance and the 3-6% capability gap vs. the absolute best models does not matter for your specific tasks. For those workloads, the price difference is transformational, not marginal.
It is not worth using as a wholesale replacement for Claude Opus 4.7 or GPT-5.5 in production environments that require enterprise compliance, maximum capability on complex agent tasks, or reliable responses outside of technical domains.
The most defensible use is a tiered architecture: V4-Flash for bulk throughput tasks, V4-Pro for intermediate-complexity coding and reasoning, and a premium closed model for the tasks where quality is non-negotiable. That split captures the cost advantage where it is largest while keeping the capability ceiling where your hardest tasks need it.
The permanent pricing announcement is what changes the calculus. If this were a promotional rate, the sensible response would be to wait and see. DeepSeek has explicitly called it the market floor. At $0.87/M output, V4-Pro is now a serious option for production AI at a price tier that did not exist a year ago.
Frequently asked questions
Yes. The web and mobile chat interface at chat.deepseek.com is free with no query limits for registered users, covering both V4-Pro and V4-Flash. The API is paid, with V4-Pro at $0.435/M input and $0.87/M output, and V4-Flash at $0.14/M input and $0.28/M output. The open weights are free to download from Hugging Face under the MIT license; self-hosting requires significant GPU resources.
It depends on your compliance requirements. The managed API stores data in China under Chinese cybersecurity law, making it unsuitable for GDPR, HIPAA, and US government workloads without self-hosting. Self-hosting on your own infrastructure with the MIT-licensed weights eliminates data residency concerns, but requires approximately 8x H100 GPUs for V4-Pro or 2-4 for V4-Flash. There are no enterprise SLAs or formal compliance certifications for the managed API as of June 2026.
V4-Pro in Max mode scores 80.6% on SWE-bench Verified, compared to Claude Opus 4.7 at roughly 87.6% and GPT-5.5 at 78-80% (estimated). DeepSeek's own technical report estimates V4 trails the absolute frontier by approximately 3-6 months on capability. On cost, V4-Pro is roughly 34x cheaper on output than both Claude Opus 4.7 and GPT-5.5. For most high-volume production tasks, V4-Pro is competitive; for the most demanding agentic workflows, Claude Opus 4.7 leads.
Use deepseek-v4-pro and deepseek-v4-flash as model IDs. The legacy aliases deepseek-chat and
deepseek-reasoner currently map to V4-Flash but will be permanently retired on July 24, 2026.
Migrate any integrations using those strings before that date.
Yes. Both variants are available on Hugging Face under the MIT license. V4-Flash is 160GB and can be served with 2-4 high-end GPUs (H100/H200) using vLLM or SGLang. V4-Pro is 865GB and requires approximately 8x H100/H200 GPUs for full-precision tensor-parallel serving. Self-hosting eliminates data residency concerns and removes per-token API costs, at the expense of infrastructure investment and operational overhead.