Google I/O 2026: Gemini 3.5 Flash GA and the Flash-First Shift
Google I/O 2026 recap: Gemini 3.5 Flash GA beats last gen's Pro tier, Gemini Omni video, Antigravity 2.0, Gemini Spark, and a 10x Flash price surprise.

Google I/O 2026 had one structural event that outweighed everything else on the announcements list. For the first time, a Flash-tier model outperformed the previous generation's Pro tier on coding and agentic benchmarks. When the fast, cheap model beats last year's premium model on the tasks developers actually build, the entire AI pricing market has to recalibrate.
Gemini 3.5 Flash shipped generally available on May 19 the same moment it was announced: no waitlist, no preview period, immediately the default model across the Gemini app, AI Mode in Google Search, and the Gemini API. Within hours it was handling 900 million monthly Gemini app users. That is how Google uses its distribution advantage.
The rest of I/O was organized around a coherent strategic statement: Google is no longer shipping isolated AI features. It is building an agent that exists alongside the user.
Gemini 3.5 Flash: what the benchmark inversion actually means
Gemini 3.5 Flash scores 76.2% on Terminal-Bench 2.1 (coding evaluation) and 1,656 Elo on GDPval-AA (real-world agentic task performance). Both numbers beat Gemini 3.1 Pro (last generation's premium tier) on the benchmarks developers weight most.
The practical implication: the "fast, cheap, or smart, pick two" trade-off is over for the tasks that comprise most production workloads. Coding assistance, agentic task execution, RAG retrieval, structured output, document analysis: Flash now handles all of them at Pro-equivalent quality.
The speed advantage is significant in its own right. Gemini 3.5 Flash delivers more than 280 output tokens per second, approximately four times faster than comparable frontier models. For latency-sensitive pipelines, that gap matters operationally.
The context window is 1 million tokens. Function calling, structured output, code execution, and search-as-a-tool are built into the model, not delegated to external orchestration libraries. Dynamic thinking levels let developers tune reasoning depth per request rather than switching models.
Pricing is $1.50 per million input tokens, $9.00 per million output tokens. Cached input drops to $0.15 per million, a 90% discount that meaningfully changes the economics of repeated-context workflows like multi-turn agents and large document analysis pipelines.
The 10x Flash price increase: Gemini 3.5 Flash costs $1.50/million input tokens. The previous Flash tier cost approximately $0.15/million. That is a 10x increase. The cached input price ($0.15/million) matches the old uncached rate and provides real relief for repeated-context workflows, but developers who built pipelines on old Flash pricing are absorbing a significant cost jump on uncached requests.

Gemini Omni Flash, Antigravity 2.0, and Gemini Spark
Gemini Omni Flash is the other major model announcement. Where previous video generation models accept text or image prompts, Omni was trained simultaneously on text, audio, image, and video, enabling it to understand the physical and semantic relationships between modalities rather than pattern-matching visual output.
The demonstration that drew the most technical attention: a protein folding sequence (amino acid chains twisting into secondary structures) with synchronized narration, generated as a physically accurate stop-motion video. The model understood the biochemistry; it did not just generate plausible-looking animation. Conversational editing lets users describe changes in plain language and have the model apply them while maintaining character consistency and continuity across scenes.
Gemini Omni Flash is available to AI Plus, Pro, and Ultra subscribers, and on YouTube Shorts at no cost for users 18 and older. Developer API access is "coming in the coming weeks" and was not live at launch.
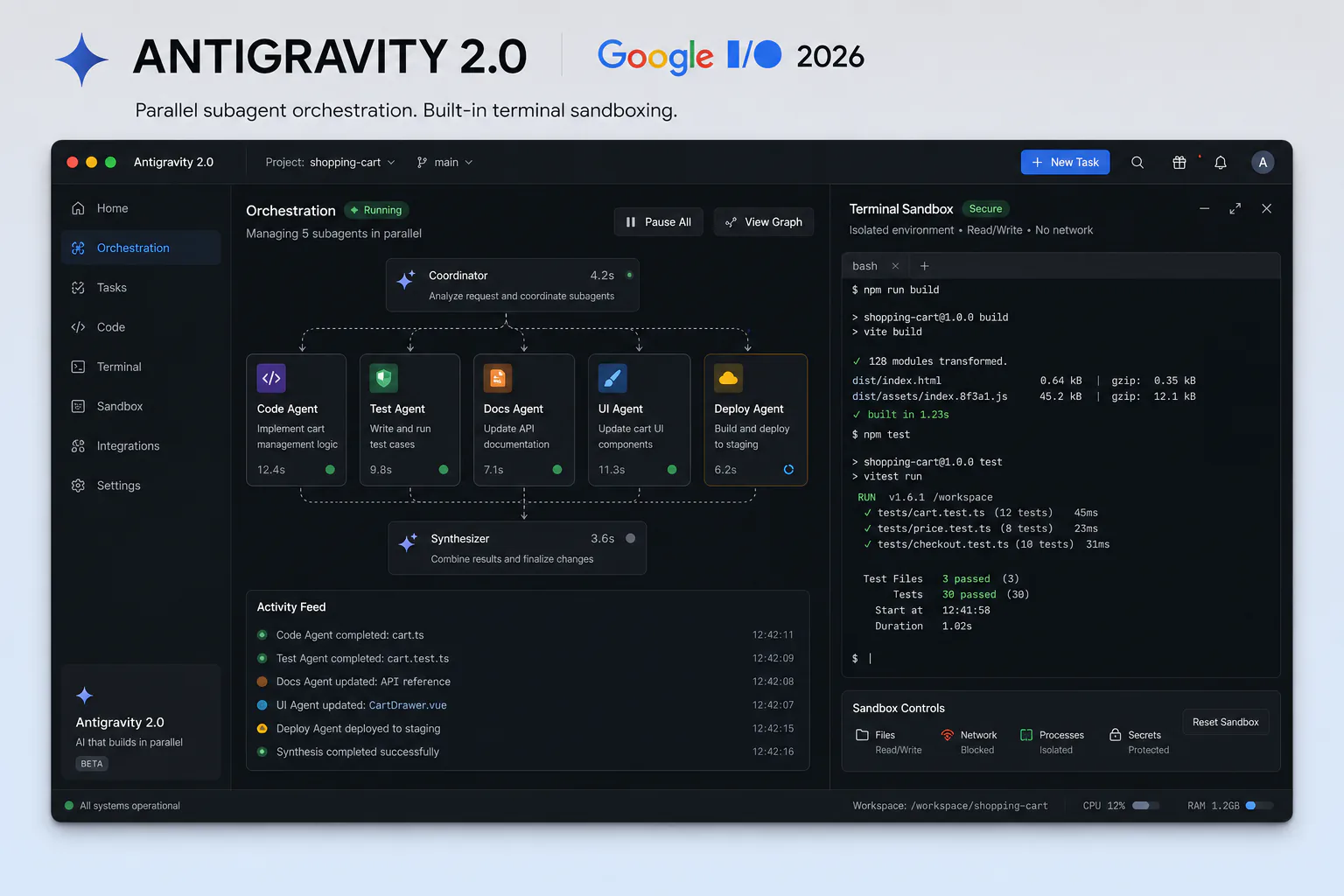
Antigravity 2.0 is Google's agent-first development platform, shipping as a standalone desktop application and CLI. The headline I/O demo: building a functioning operating system in 12 hours using 93 parallel subagents, 15,000-plus model requests, 2.6 billion tokens, and under $1,000 in API credits. Whether the OS was production-quality is secondary. The demo proved that parallel agentic workflows at that scale are economically viable at Flash pricing in a way they simply are not at Pro or flagship pricing.
One important warning for developers: the Gemini CLI tool (100,000-plus GitHub stars, built with 6,000-plus community pull requests) retires June 18, 2026, just 28 days from I/O. Antigravity CLI is its replacement. Unlike Gemini CLI, Antigravity CLI is not open-source for non-enterprise users. Teams with Gemini CLI in CI/CD pipelines, onboarding documentation, or GitHub Actions have under two weeks to migrate.
Gemini Spark is the consumer piece: a 24/7 personal AI agent that operates in the background, including when your phone is off, surfacing a personalized daily brief and integrating with Google Workspace for organizational context. Spark is currently gated to AI Ultra subscribers in the US. There is no public developer API. It is a design pattern worth studying, not a platform to build on yet.
The AI Ultra plan dropped from $250 to $100 per month, the most direct signal of where Google sees the competitive price ceiling for advanced AI subscriptions.
The takeaway
The strategic headline from I/O 2026 is the Flash/Pro inversion. Every competing AI provider now faces pressure to either close the capability gap or reduce prices. The pricing cascade is already visible: GPT-5.5, Gemini 3.5 Flash, and Claude Opus 4.8 shipped within five weeks of each other. Multi-model routing (sending the right task to the cheapest capable model) is becoming standard enterprise architecture, not a configuration choice for power users.
Gemini 3.5 Flash is the practical pick for cost-sensitive, high-volume pipelines. Claude Opus 4.8 and GPT-5.5 hold edges on long-context and complex reasoning tasks respectively. For most production workloads, Flash handles 70-80% at $1.50/million input, with Pro or flagship reserved for the slice that demonstrably requires it.
For teams building on AI, the Gemini CLI deadline (June 18) is the immediate action item. The Flash pricing change and the Antigravity CLI migration are both decisions that affect infrastructure costs and CI/CD pipelines right now, not in Q3.
For how Google is landing Gemini on consumer devices, read our Apple-Google Gemini deal breakdown. For private deployment alternatives, our self-hosted LLM guide covers the cost crossover math. For browser-based AI workflows, see the AI browser research tools comparison and AI tools hub.
Frequently asked questions
Yes. Gemini 3.5 Flash shipped generally available on May 19, 2026, the day it was announced at
Google I/O. You can access it via the Gemini API in Google AI Studio or Vertex AI using the model
ID gemini-3.5-flash. No waitlist or preview access is required. Pricing is $1.50 per million
input tokens and $9.00 per million output tokens, with cached input at $0.15 per million.
On coding and agentic benchmarks (Terminal-Bench 2.1, GDPval-AA), Gemini 3.5 Flash leads or matches both at roughly one-third the input token cost. Claude Opus 4.8 holds an edge on repository-level engineering precision and complex reasoning. GPT-5.5 leads on shell and CLI automation tasks. For most production pipelines, Gemini 3.5 Flash handles the volume workload while Pro or flagship models handle the tasks that demonstrably require them.
Google announced at I/O 2026 that Gemini CLI (an open-source tool with 100,000-plus GitHub stars) retires on June 18, 2026. Its replacement is Antigravity CLI, which is not open-source for non-enterprise users. If your team uses Gemini CLI in CI/CD pipelines, GitHub Actions, or onboarding scripts, you have until June 18 to migrate to Antigravity CLI. The 28-day migration window from the I/O announcement is tight for teams with deep CLI integrations.