Kubernetes for AI Workloads: What Developers Need to Know (2026)
How DRA, gang scheduling, llm-d, and Kubernetes v1.36 transform GPU infrastructure for AI in 2026. Practical guide for platform engineers and ML developers.
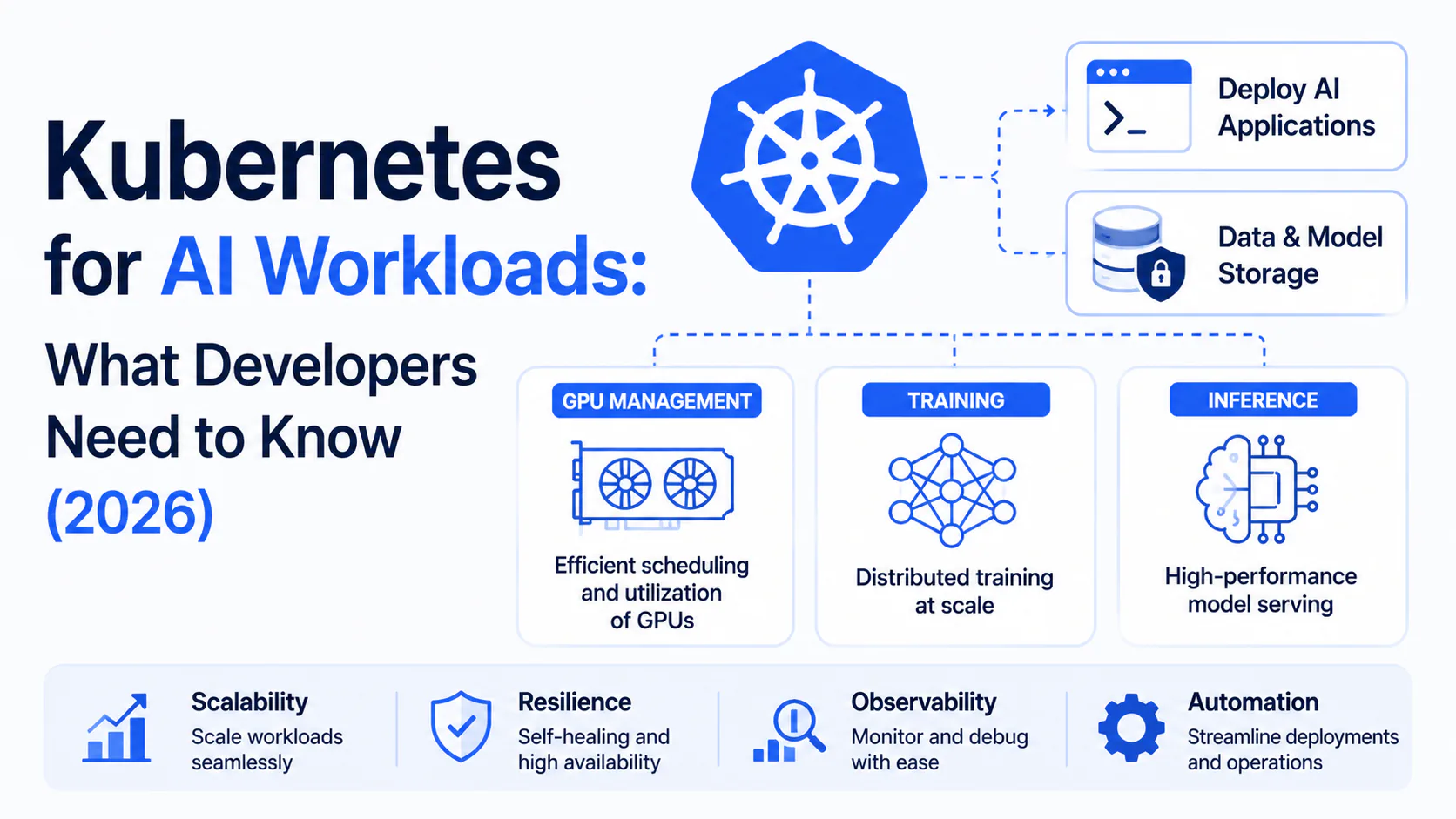
Running AI workloads on Kubernetes used to mean fighting the platform. GPU scheduling was primitive, distributed training required brittle custom operators, and inference at scale demanded deep YAML expertise most ML teams didn't have.
That era is over. The 2025-2026 inflection point, driven by Dynamic Resource Allocation graduating to GA, NVIDIA open-sourcing its GPU driver to CNCF, and Kubernetes v1.36 shipping native gang scheduling, has turned Kubernetes into a genuinely capable AI infrastructure substrate. The 2026 CNCF Annual Survey found that 66% of organizations running generative AI inference now use Kubernetes to manage some or all of those workloads.
This guide covers the key architectural shifts, the tools that now make up the standard AI/ML stack, the real limitations you will hit, and how to decide whether Kubernetes is the right choice for your workload.
A note on "Kubernetes 2.0": This phrase circulates in the developer community to describe the platform's qualitative leap for AI workloads, not a literal version number. Kubernetes versioning continues at v1.35, v1.36, etc.
What actually changed in Kubernetes for AI
Before 2025, the fundamental problem was that Kubernetes' scheduler was blind to GPU specifics. You could request nvidia.com/gpu: 1 and get a GPU. Which GPU? What memory? What NVLink topology? The scheduler had no idea. This made intelligent placement impossible.
Three changes in 2025-2026 fixed the foundational issues.
Dynamic Resource Allocation (DRA) replaces the Device Plugin model
The legacy Device Plugin API, introduced in 2017, expressed GPU resources as integer counts. DRA replaces it entirely. Under the new model, NVIDIA's driver publishes structured ResourceSlice custom resources to the Kubernetes API, exposing GPU attributes: memory size, NVLink fabric, MIG partition capability, and topology placement.
Workloads request specific configurations via ResourceClaim or ResourceClaimTemplate. The scheduler can now make GPU placement decisions with the same precision it brings to CPU and memory.
DRA graduated to General Availability in Kubernetes 1.34. At KubeCon Europe 2026, NVIDIA donated its GPU DRA driver to CNCF, and Google open-sourced its DRA TPU driver. Both leading AI hardware vendors now treat DRA as the standard interface.
Here is what a ResourceClaim looks like in practice:
apiVersion: resource.k8s.io/v1alpha3
kind: ResourceClaimTemplate
metadata:
name: gpu-h100-80gb
spec:
spec:
resourceClassName: nvidia.com/gpu
parametersRef:
apiGroup: gpu.resource.nvidia.com
kind: GpuClaimParameters
name: h100-80gb-params
---
apiVersion: gpu.resource.nvidia.com/v1alpha1
kind: GpuClaimParameters
metadata:
name: h100-80gb-params
spec:
count: 1
selector:
memory: 80Gi
model: H100Migration note: Teams running GPU workloads on the legacy NVIDIA Device Plugin cannot remove
it overnight. Migrating to DRA requires updating deployment manifests and testing ResourceClaim
configurations. Plan for this as a dedicated project, not an afternoon task.
Native gang scheduling for distributed training
AI training jobs break a core assumption of web-workload scheduling: they require dozens or hundreds of GPUs to be available simultaneously, or the job cannot start at all. Without gang scheduling, a training job requesting 64 GPUs might partially schedule, consuming resources and blocking other workloads while waiting for the rest. This resource fragmentation deadlock was a chronic problem.
Kubernetes v1.35 introduced native gang scheduling support (KEP-4671). Kubernetes v1.36 extends it with the new Workload API and PodGroup API, making related pods a single logical scheduling entity that the scheduler treats atomically.
HPA scale-to-zero for inference cost control
Kubernetes v1.36 graduates native support for scaling inference workloads to exactly zero replicas during idle periods. Previously, teams needed KEDA or Knative to achieve this. Scale-to-zero is now a first-class HPA capability, directly reducing idle GPU costs for production LLM APIs.
The 2026 Kubernetes AI stack
No single tool handles the full AI lifecycle. The current standard stack assembles several CNCF-ecosystem projects, each solving a specific layer of the problem.
Kueue: job admission and quota management
Kueue controls which jobs enter the scheduling pool and enforces GPU quotas across teams and namespaces. It manages ClusterQueue resources for organization-wide capacity pools and LocalQueue for per-namespace team budgets.
Without Kueue, large AI clusters quickly become ungovernable: high-priority training jobs starve inference workloads, teams over-consume shared GPU budgets, and expensive hardware sits idle while jobs queue informally. Kueue solves all three.
The Kubernetes AI Conformance Program mandates Kueue support for conformant clusters.
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: ml-team-cluster-queue
spec:
namespaceSelector: {}
resourceGroups:
- coveredResources: ["nvidia.com/gpu", "cpu", "memory"]
flavors:
- name: "h100-80gb"
resources:
- name: "nvidia.com/gpu"
nominalQuota: 16 # guaranteed allocation
borrowingLimit: 8 # can borrow up to 8 more from cohort
- name: "a100-40gb"
resources:
- name: "nvidia.com/gpu"
nominalQuota: 8KubeRay: distributed training and fine-tuning
KubeRay is the de facto standard for distributed training on Kubernetes. It exposes RayCluster, RayJob, and RayService custom resources that abstract the complexity of managing distributed Python processes across GPU nodes. It integrates with PyTorch, TensorFlow, and JAX, and supports Ray Tune for hyperparameter sweeps.
The 2026 consensus has settled on KubeRay over running Ray directly on VMs. Running Ray on raw VMs loses Kubernetes' multi-tenancy, network policies, and GitOps integrations.
apiVersion: ray.io/v1
kind: RayJob
metadata:
name: llm-finetune-job
spec:
entrypoint: python finetune.py --model llama-3-8b --dataset internal
runtimeEnvYAML: |
pip:
- transformers==4.44.0
- peft==0.12.0
rayClusterSpec:
rayVersion: "2.35.0"
headGroupSpec:
rayStartParams:
num-cpus: "4"
template:
spec:
containers:
- name: ray-head
image: rayproject/ray:2.35.0-gpu
workerGroupSpecs:
- groupName: gpu-workers
replicas: 4
minReplicas: 4 # gang scheduling: all 4 or nothing
maxReplicas: 4
rayStartParams:
num-gpus: "8"
template:
spec:
containers:
- name: ray-worker
image: rayproject/ray:2.35.0-gpu
resources:
limits:
nvidia.com/gpu: "8"llm-d: distributed LLM inference
llm-d is a Kubernetes-native open-source framework for distributed LLM inference, accepted into CNCF Sandbox at KubeCon Europe 2026. It was a collaborative effort from Red Hat, Google Cloud, IBM Research, CoreWeave, and NVIDIA, built to support any model, any accelerator, any cloud.
llm-d introduces inference-aware traffic management, native orchestration for multi-node replicas, and advanced KV cache management with hierarchical offloading. For organizations deploying large models (70B+ parameters) that require tensor parallelism across multiple GPUs, llm-d replaces the previous approach of ad hoc multi-node vLLM configurations.
KServe, vLLM, and KubeAI: the serving layer
For the model serving layer, three options now dominate:
- KServe provides standardized model serving ingress via the
InferencePoolresource and works well for multi-model serving environments with heterogeneous frameworks. - vLLM (with PagedAttention and continuous batching) is the standard for high-throughput LLM serving when latency and throughput optimization are priorities.
- KubeAI (v0.23.2) has seen broad adoption for its minimal dependency footprint and prefix-aware load balancing, which improves KV cache hit rates in shared-prompt or RAG configurations.
KAI Scheduler: GPU-specific scheduling intelligence
KAI (Kubernetes AI Scheduler), accepted as a CNCF Sandbox project at KubeCon Europe 2026, adds a GPU-specific intelligence layer on top of standard Kubernetes scheduling. It handles bin-packing, gang scheduling, fair-share allocation, GPU topology awareness, fractional GPU sharing via MIG partitioning or time-slicing, and hierarchical quota management for multi-tenant teams.
KAI Scheduler integrates with Kueue for quota enforcement and with DRA for GPU topology awareness. The combination covers scenarios that would require significant manual configuration otherwise.
Kubernetes v1.36 "Haru": the AI-focused release
Released April 22, 2026 with 70 enhancements, v1.36 is the most AI-oriented Kubernetes release to date. The changes that matter most for AI workloads:
Workload-Aware Gang Scheduling (Alpha to Beta path): The new Workload API and PodGroup API decouple template definition from runtime state. Atomic scheduling of related pod groups is now a scheduler-native capability rather than a third-party add-on.
In-Place Pod Resource Resizing (stable path): LLM inference pods can now adjust compute resources without restarting. This is critical for dynamic load handling: a pod can scale its GPU allocation up during a traffic spike and back down without the cold-start penalty of a full restart. The new ResizeDeferred event handles cases where insufficient node capacity requires a retry.
Fine-Grained Kubelet API Authorization (GA): Least-privilege access to kubelet endpoints, relevant for regulated AI deployments under DORA, NIS2, or the EU AI Act.
Pod-Level Hardware Health Reporting: Better visibility into GPU and accelerator health for faster failure detection in distributed training clusters.
The Kubernetes AI Conformance Program
Launched at KubeCon North America 2025 and expanded at KubeCon Europe 2026, this CNCF program defines Kubernetes AI Requirements (KARs): a formal certification standard for clusters running AI workloads. By KubeCon Europe 2026, 31 platforms had achieved certification.
Certified clusters must support: DRA, Kueue integration, HPA scaling on custom AI metrics, in-place pod resizing without restart, workload-aware scheduling, and agentic workload validation (added in 2026).
The practical implication: if a managed Kubernetes offering is AI Conformance certified, you can rely on a predictable set of capabilities regardless of whether you are on GKE, AKS, EKS, or a bare-metal distribution. The same workload manifests should run without modification.
Real-world deployment patterns
Multi-team GPU sharing
A platform team uses Kueue ClusterQueues to allocate GPU quotas across data science, ML engineering, and product teams. KAI Scheduler enforces bin-packing and fair-share within each team's budget. MIG partitioning allows smaller fine-tuning jobs to share H100s with inference workloads. Teams submit jobs without needing to know cluster topology.
The key configuration is the Kueue ClusterQueue cohort: teams can borrow unused quota from a shared pool when their own allocation is insufficient, with priority policies preventing lower-priority jobs from starving high-priority inference.
Production LLM inference with scale-to-zero
The canonical 2026 pattern: deploy a self-hosted LLM using vLLM or KubeAI on Kubernetes, fronted by the Gateway API Inference Extension with InferencePool routing. Kueue manages request admission. HPA scale-to-zero cuts GPU costs during off-peak hours. DRA ensures each inference pod gets the optimal GPU configuration without manual node labeling.
This replaces what previously required KEDA, a custom autoscaler, and manual GPU node affinity rules.
Hybrid cloud with data residency requirements
A regulated organization can run AI inference on bare-metal for data residency requirements using a distribution like Nutanix Kubernetes Platform, while bursting training jobs to GKE Spot instances for cost efficiency. With DRA and AI Conformance as the common standards, the same workload manifests run on both environments without modification.
Where Kubernetes still struggles
Kubernetes is the right answer for a lot of AI infrastructure. It is not the right answer for everything. Know where it breaks down before you commit.
Operational complexity remains high. Setting up a single-node GPU workload with DRA is achievable in an afternoon. Building a production multi-tenant distributed training cluster with proper Kueue quotas, gang scheduling, KubeRay, and version compatibility across all components is a significant engineering investment. The CNCF survey cites skills gaps and operational complexity as top adoption barriers even for teams already using Kubernetes.
Version compatibility between components is a first-class concern. Version drift between the Ray Operator and Kueue's admission webhook is a documented source of jobs that appear queued but never schedule. Before upgrading any component in the AI stack, check compatibility matrices explicitly.
GPU debugging is still immature. Pod-level hardware health reporting improved in v1.36, but GPU failure modes in distributed training (silent data corruption, NVLink fabric failures, thermal throttling) remain difficult to detect and attribute. OpenTelemetry for GPU metrics is still maturing.
Not a managed ML platform. Kubernetes does not replace SageMaker, Vertex AI, or Azure ML for teams that want experiment tracking, model registry, automated retraining pipelines, and built-in MLOps tooling out of the box. Each of those capabilities requires separately adding and operating tools like MLflow and Kubeflow Pipelines.
Small deployments often do not justify the overhead. For a single-model inference API on a single cloud without multi-tenancy requirements, running managed inference (AWS Bedrock, Vertex AI Model Garden, Azure AI Foundry) is simpler. Kubernetes' value scales with complexity. At small deployments, the operational overhead often outweighs the benefits.
Kubernetes vs. managed ML platforms
| Dimension | Kubernetes | Managed ML Platforms |
|---|---|---|
| Setup complexity | High | Low |
| Multi-cloud portability | High (with DRA/CNCF stack) | Low (vendor lock-in) |
| Cost at scale | Lower (with optimization) | Higher (managed markup) |
| Built-in MLOps tooling | Requires ecosystem assembly | Included |
| Multi-tenancy control | Excellent (Kueue + MIG) | Limited |
| GPU hardware choice | Broad (NVIDIA, AMD, TPU via DRA) | Platform-dictated |
| Operational expertise required | High | Low to medium |
Most mature organizations run both: Kubernetes as the infrastructure substrate, with MLflow or similar tooling layered on top for experiment tracking and model registry.
Who should run AI on Kubernetes
Use Kubernetes for AI workloads if:
- Your teams need multi-cloud or on-prem portability, and vendor lock-in on GPU scheduling is a genuine concern
- You are managing GPU resources across multiple teams with different quota requirements, priorities, and workload types
- You are already running Kubernetes for application workloads and want a unified control plane rather than operating separate AI infrastructure
- Your compliance requirements (DORA, NIS2, EU AI Act) need fine-grained kubelet authorization and auditable infrastructure
- Your models are large enough to require distributed inference (tensor parallelism across multiple GPUs)
Use managed ML platforms or cloud inference instead if:
- You have a single model to serve with no multi-tenancy requirements
- Your team has no Kubernetes expertise and no plans to build it
- You need MLOps tooling (experiment tracking, model registry, pipeline orchestration) without the overhead of assembling it from open-source components
- You are optimizing for time-to-production, not long-term infrastructure cost or portability
Key takeaways
Kubernetes has genuinely earned its position as the default AI infrastructure substrate for organizations running workloads at scale. The combination of DRA (now CNCF-governed), gang scheduling, Kueue, and llm-d closes the gaps that made GPU workloads painful in prior years.
The shift matters in practice: organizations can now write a workload manifest once and run it on GKE, AKS, EKS, or bare-metal without rewriting GPU configuration. That was not possible two years ago.
What it does not do is simplify AI infrastructure for teams without Kubernetes expertise. The stack is powerful and increasingly principled, but it is still assembled from a dozen components with their own upgrade cycles. If you are evaluating whether to invest, the honest question is whether your workloads have enough complexity and scale that the operational overhead pays off. For large multi-tenant GPU clusters, it almost certainly does. For small single-model deployments, probably not yet.
If you are already running Kubernetes, start by enabling DRA and deploying Kueue before anything else. They solve the two most painful problems (GPU specificity and resource governance) and are prerequisites for everything else in the stack.
For further reading on deploying models on the infrastructure layer, see our guide to running private LLMs with open-weight models, the guardian agents in CI/CD tutorial for keeping AI-generated code quality in check, and the developer tools category hub.
Frequently asked questions
Yes. The 2026 CNCF Annual Survey found that 66% of organizations hosting generative AI inference now use Kubernetes to manage those workloads. The combination of DRA (GA in Kubernetes 1.34), native gang scheduling (v1.35-v1.36), and CNCF-governed tools like Kueue and llm-d has made Kubernetes a production-capable AI infrastructure substrate for most workload types.
DRA replaces the legacy Device Plugin API, which could only represent GPUs as integer counts. With
DRA, NVIDIA's driver publishes GPU attributes (memory, topology, MIG capability) as structured
Kubernetes resources. Workloads can request specific GPU configurations via ResourceClaim. The
scheduler can then make topology-aware placement decisions, which is critical for distributed
training and high-throughput inference where GPU placement directly affects performance.
It depends on your requirements. For a single model with no multi-tenancy needs, AWS Bedrock, Vertex AI Model Garden, or Azure AI Foundry are simpler and faster to operate. Kubernetes becomes the better choice when you need multi-cloud portability, multi-team GPU sharing with quota enforcement, or the ability to run the same workloads on-prem and in the cloud without rewriting infrastructure. Cost at scale also favors Kubernetes, since managed inference services carry a managed markup.
A CNCF certification standard (Kubernetes AI Requirements, or KARs) that defines a baseline capability set for clusters running AI workloads. Requirements include DRA support, Kueue integration, HPA scaling on GPU metrics, in-place pod resizing, workload-aware scheduling, and agentic workload validation. By KubeCon Europe 2026, 31 platforms had achieved certification. If you choose a conformant managed Kubernetes offering, you can rely on these capabilities being present regardless of cloud provider.
Gang scheduling ensures that a distributed training job only starts when all required pods can be scheduled simultaneously. Without it, a job requesting 64 GPUs might partially schedule, consuming resources and creating a deadlock while waiting for the remaining GPUs. Gang scheduling is essential for distributed training and large-scale fine-tuning. It is less critical for inference workloads, which are typically single-pod or small-replica deployments.


