Prompt Engineering for Structured JSON Outputs (With Examples)
Get reliable JSON from GPT, Claude, and Gemini every time. Schema design patterns, Pydantic and Instructor examples, and the mistakes that cause silent failures.
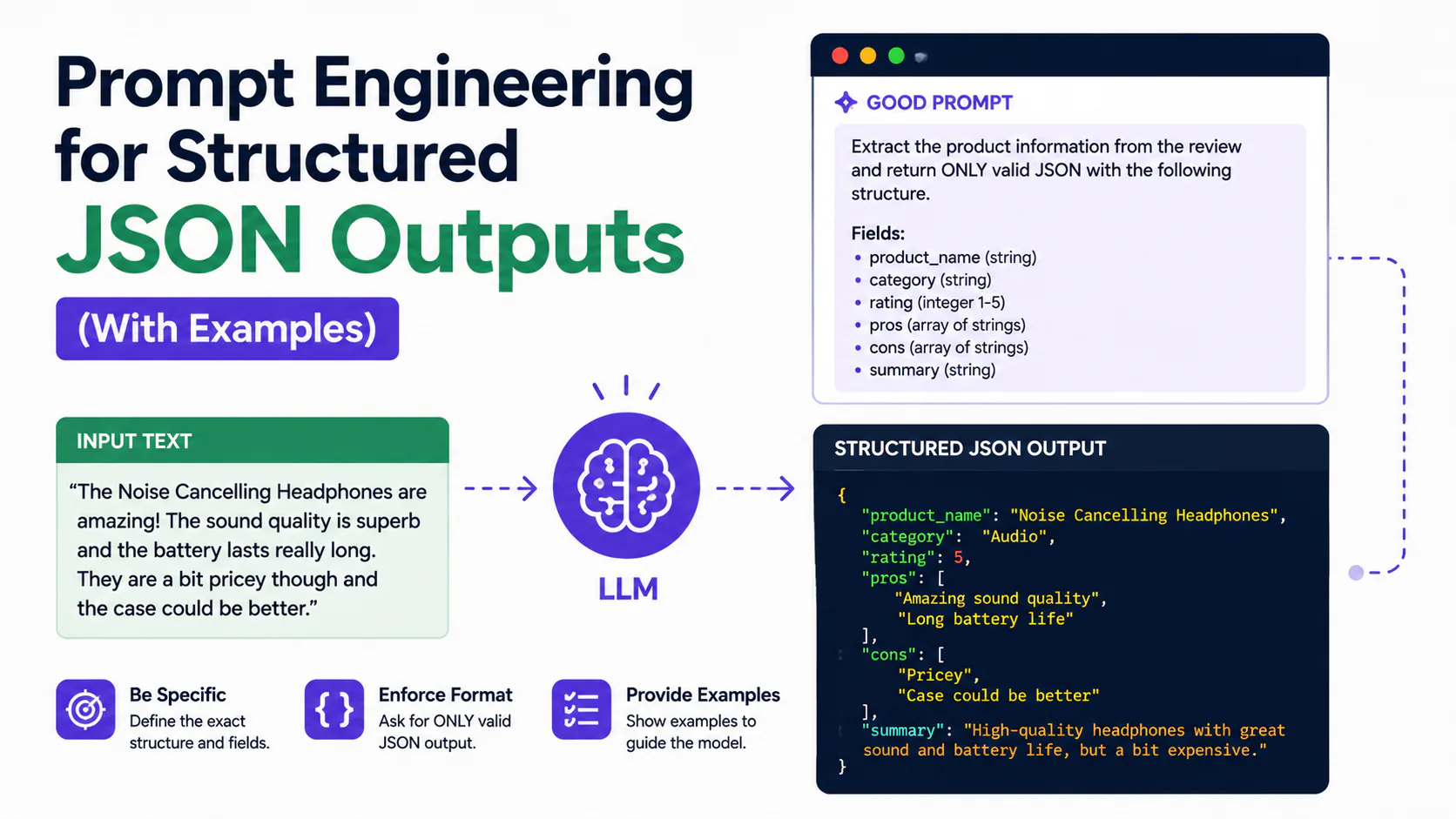
Ask an LLM for an order ID and you might get "12345," "Order #12345," or "Regarding your order, the number is 12345." Every answer is correct. Every answer breaks a parser expecting one consistent shape.
That gap between fluent prose and rigid software is exactly what structured output closes. Get it wrong and a model update can quietly corrupt a downstream dashboard for a week before anyone notices. Get it right and the model becomes physically incapable of returning a token that violates your schema.
This guide covers the schema design patterns that actually move the needle, working code for OpenAI, Anthropic, and self-hosted models, and the specific ways structured output still breaks even when it technically validates.
TL;DR: Use your provider's native strict-mode enforcement first. Define schemas with Pydantic
or Zod instead of hand-written JSON Schema. Keep nesting to 2 to 3 levels, make missing data
optional instead of required, and put a reasoning field before your answer fields.
Why prompting alone was never enough
Politely asking a model to "return JSON" is the oldest trick in the book, and it is unreliable by design. There is no mechanism forcing compliance, so the model can drift into invalid syntax, rename a field, or wrap the JSON in a friendly sentence.
OpenAI's own benchmark shows how bad that drift gets. On a complex JSON schema following test, gpt-4-0613 scored under 40% without dedicated tooling. With Structured Outputs enabled, gpt-4o-2024-08-06 scored 100% on the same benchmark.
That is not a marginal improvement. It is the difference between a feature you can build a product on and one you have to babysit with retries and regex.
The three generations of solving this problem
Structured output has moved through three distinct stages, and knowing where each one falls short tells you what to reach for today.
Generation 1: prompt-only
Clear instructions plus an example output plus hope. This works with any model, including ones with zero native support, but it sits at the bottom of every reliability hierarchy published by major providers. Use it only for throwaway prototypes.
Generation 2: JSON mode
A provider-level guarantee that the output will parse as JSON, with no guarantee it matches your schema. A model can still hand back syntactically perfect JSON with the wrong field names or a missing required value. JSON mode is a half-step, not a fix.
Generation 3: constrained decoding
The current standard across OpenAI, Anthropic, Google, and self-hosted engines like vLLM and SGLang. The schema constrains the token generation process itself, so an invalid token is never produced in the first place. This moves schema compliance from a prompt-engineering problem to an infrastructure guarantee.
Schema design patterns that actually change output quality
Constrained decoding guarantees structure, not content quality. Four patterns consistently show up across independent technical guidance as the highest-leverage levers you control.
Reasoning-first field ordering. Models generate tokens left to right, so field order is effectively prompt order. Put a reasoning field before your answer fields and the model works through the problem before committing, turning chain-of-thought into a structural property of the schema instead of a separate instruction.
Descriptive field names and description strings. In Pydantic and similar typed systems, a field's description string becomes part of the JSON Schema sent to the model. It is documentation and a live prompt at the same time.
Explicit nulls over forced requirements. If a value might not exist in the source text, make the field optional. Forcing a required field when the data is not there is a direct cause of hallucination, because the model has to invent something rather than report absence.
Shallow nesting. Two to three levels of nesting is the ceiling for both accuracy and schema compilation speed. Deeply nested schemas raise error rates and slow down the one-time grammar compilation step that constrained decoding depends on.
Here is one schema applying three of those patterns at once:
from pydantic import BaseModel, Field
from typing import Optional, List
class LineItem(BaseModel):
description: str
quantity: int
unit_price: float
class Receipt(BaseModel):
# Reasoning field comes first: chain-of-thought baked into the schema
reasoning: str = Field(description="Brief notes on what was found before extraction")
merchant_name: str # Optional with an explicit null fallback, never forced
transaction_date: Optional[str] = Field(default=None, description="ISO 8601 date if present, else null")
line_items: List[LineItem] # one level of nesting, not deeper
total: floatHow each provider actually implements this
The mechanism converges on JSON Schema everywhere, but the API surface for supplying it differs by provider.
OpenAI: Structured Outputs with strict mode
OpenAI ships this as a json_schema response format or as strict: true on a tool definition. Both the Python and JavaScript SDKs accept a Pydantic model or Zod schema directly, so you never hand-write raw JSON Schema.
from pydantic import BaseModel
from openai import OpenAI
client = OpenAI()
class CalendarEvent(BaseModel):
name: str
date: str
participants: list[str]
response = client.responses.parse(
model="gpt-5.5",
input=[
{"role": "system", "content": "Extract the event information."},
{"role": "user", "content": "Alice and Bob are going to a science fair on Friday."},
],
text_format=CalendarEvent,
)
event = response.output_parsedNote the one-time cost: the first call with any new schema is slower, since OpenAI preprocesses it into a context-free grammar before generation. Reusing the same schema on later calls does not pay that cost again.
Anthropic: tool-based structured output
Claude has no separate JSON mode toggle. You define the schema as a tool, and Claude enforces structure through its tool-use mechanism, even when the actual goal is data extraction rather than an external action.
Google: native schema enforcement in Gemini
Gemini enforces schemas natively through the API and Vertex AI. You supply a strict JSON schema and Gemini guarantees compliance in the response, with implementation details that differ enough from OpenAI and Anthropic to need separate integration code.
Self-hosted: grammar-based constrained decoding
vLLM, SGLang, and similar local inference engines support the same fundamental mechanism on your own hardware. XGrammar is the default backend for several of them and is vendor-quoted at up to 100x the throughput of older constrained-decoding approaches, with near-zero overhead on JSON generation specifically. Outlines pioneered grammar-based generation in open source and is itself integrated as a selectable backend inside vLLM and SGLang.
If you are already running your own inference stack for agentic tool calling, our guide to setting up MCP servers for an AI agent stack covers the surrounding infrastructure these schemas plug into.
Provider-agnostic: wrapping it with Instructor
Instructor wraps Pydantic models around any supported provider's native call, adding typed validation errors and automatic retries on top of whatever enforcement the provider already gives you.
import instructor
from openai import OpenAI
from pydantic import BaseModel
class UserInfo(BaseModel):
name: str
age: int
client = instructor.from_openai(OpenAI())
user = client.chat.completions.create(
model="gpt-4.1-mini",
response_model=UserInfo,
messages=[{"role": "user", "content": "Alice is 28 years old."}],
)
print(user.name) # Alice
print(user.age) # 28This is the same code pattern regardless of which provider sits underneath, which matters if you expect to switch models later.
Structured Outputs vs. function calling
These two get confused constantly. Function calling can return a text reply and a function call in the same turn, because the model is genuinely deciding whether to act. Structured Outputs returns only the JSON, which makes it the better fit for pure data extraction where there is no decision to make, just a shape to fill in.
Why most teams combine approaches instead of picking one
The dominant production pattern is layered, not singular.
Provider strict-mode enforcement
│
(guarantees valid shape)
│
Typed schema (Pydantic / Zod)
│
(dev-time safety, IDE support)
│
Validation layer (Instructor or custom)
│
(business-logic checks the schema can't express)
│
Single repair-retry step
│
(handles the residual edge cases)Each layer catches what the one before it cannot. Strict mode cannot verify that an end date falls after a start date. A validation layer can.
Where this still breaks, even when it validates
Structural validity is not semantic correctness. A perfectly typed JSON object can still contain a hallucinated total or a fabricated entity name, so you validate the values, not just the shape.
Three other limits are worth knowing before you commit:
- Schema complexity has a real ceiling. Very large schemas degrade output quality even when they technically pass validation, so extraction tasks needing 50 or more fields are better split into multiple smaller calls.
- Reasoning models complicate the reasoning-first pattern. On models that already think step by step internally, an explicit
reasoningfield can duplicate work the model already does and slightly hurt output quality. Test this on a reasoning model before assuming the pattern still helps. - Self-hosted quality is bounded by the underlying model. A 7B local model will always produce valid JSON if your grammar engine works, but the values inside that JSON will not match what GPT-4o or Claude produces on a genuinely hard extraction task.
If you are weighing a self-hosted setup against a hosted API for exactly this tradeoff, our walkthrough on deploying a private, agent-ready LLM goes deeper into where that capability gap actually shows up.
Approach-by-approach comparison
| Approach | Guarantee | Best for | Key limitation |
|---|---|---|---|
| Prompt-only | None | Quick prototypes | Format drift at any temperature above near-zero |
| JSON mode | Syntax only | Legacy fallback | No guarantee fields match your schema |
| OpenAI strict mode | Full compliance | Production extraction on OpenAI | Schema complexity ceiling, first-call latency |
| Anthropic tool-based | Full compliance | Teams already using Claude tools | No separate JSON mode toggle |
| Gemini native schema | Full compliance | Teams standardized on Google | Separate integration code per provider |
| Instructor | Full compliance + retries | Multi-provider codebases | Adds a dependency layer |
| Self-hosted grammar decoding | Full compliance | Privacy or air-gapped needs | Bounded by the open model's raw quality |
What to build first
The highest-leverage starting point for most teams is not a complex extraction pipeline. It is support ticket routing: a small schema with enums for category, urgency, and destination, one validation pass, and one repair retry. It is small enough to ship in a day and produces immediate, measurable downstream value.
From there, document and receipt extraction, calendar event parsing, and agentic tool-call arguments all reuse the exact same schema design patterns covered above.
FAQ
Frequently asked questions
Not as a separate toggle. Claude achieves the same result through its tool-use mechanism: you define a schema as a tool, and Claude enforces it with type safety when it calls that tool, even when your real goal is extraction rather than an action.
Use Pydantic or Zod. Both providers' SDKs accept these objects directly, and you get type coercion, validation, and automatic schema generation for free instead of hand-maintaining raw JSON Schema.
OpenAI and similar engines preprocess each new JSON schema into a context-free grammar before the first generation. That one-time compilation cost disappears on later calls reusing the same schema.
They overlap but are not identical. Function calling can return text and a function call in the same turn because the model is deciding whether to act. Structured Outputs returns only the JSON, which fits pure data extraction better.
Keep nesting to two or three levels. That is consistently cited as the single most impactful schema design choice for accuracy, and deeper nesting also slows down grammar compilation.
Key takeaways
Constrained decoding is the production answer in 2026, not prompt-only requests and not legacy JSON mode. Pick your provider's native strict mode first, wrap it in Pydantic or Zod for development-time safety, and add Instructor or a custom validator for the business-logic checks a schema cannot express on its own.
Schema design still matters even after you turn strict mode on. Reasoning-first ordering, explicit nulls, descriptive fields, and shallow nesting are the four levers that separate a schema that merely validates from one that actually produces accurate data.
Start with a small, real use case like ticket routing before reaching for a 50-field extraction schema. The discipline scales up far better than the complexity does.

